 "9.11"搜索结果 1 条
"9.11"搜索结果 1 条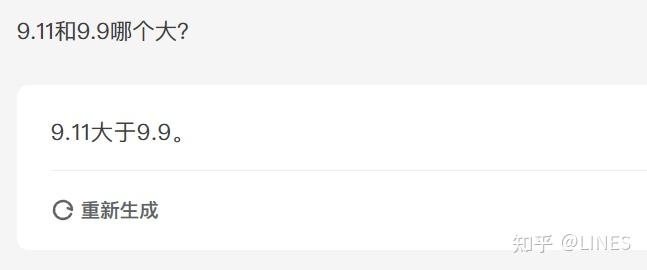
为什么会有那么多大模型答错「9.9 和 9.11 哪个大」?
省流:不是tokenizer的问题,也不是注意力错误,也不是语义建模错误。我不知道为什么,这简直是这几天最令我困惑的事情了。 最简单的回答是归咎于tokenizer,但这很可能是过度简化了问题。 对于其他答主提及的gpt4o等模型,其tokenizer可以从openai的网站或tiktoken获得,其将 11 分词为一个token并不能证明是直接导致该现象的原因。 我们可以很简单地找到反例。如llama系列,从第一代开始其tokenizer就将单个数字作为分词。baic…