现有的汉字输入法还能进一步改进吗?
通过前面介绍的通信系统模型来分析汉字编码输入系统,将汉字编码输入系统的特殊性整合到通信系统模型中,从而建立起一种基于信息论的汉字编码输入系统模型(参见图3.2),以便指导我们的汉字编码输入实践,设计和开发出更好的汉字编码输入法。
在图3.2中,M代表消息,C代表编码,S’代表编码的内码,M’代表消息的内码。与信息论中的通信系统模型相比,该图中的模型仅仅是多了一个反向信道,而其它部分都是相同的,相当于一个带反馈的通信系统。虽然模型中各部分的具体含义与典型的通信系统中的相应部分大不相同,但是信息论中的普遍结论仍然是成立的。
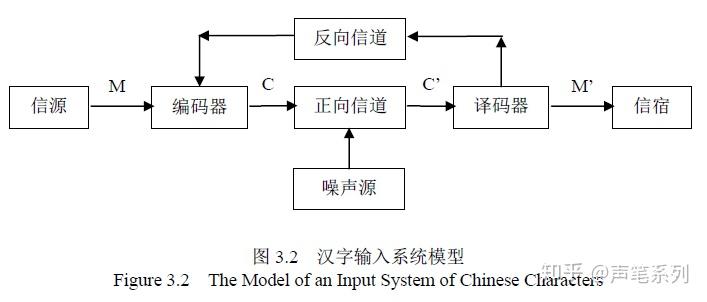
汉字编码输入系统的信源
在汉字编码输入系统这个特殊的通信系统中,充当信源的是输入人员,而不是一般的电子设备。输入人员是一种离散信源,他产生的消息序列就是待输入的文本。消息可以是单个的字符,也可以是字符的序列。消息中不仅包括汉字,还包括标点、符号、拼音等,不仅包括全角字符还可以包括半角字符。所有的这些符号一起构成了源字母表。在中文信息处理领域,该字母表通常被称为“信息交换用汉字编码字符集”。在不同的国家和地区,以及在不同的时期,这个字符集的大小和包含的具体字符是不同的。台湾在字符集方面有自己独立的BIG5工业标准。另外,日本、韩国也在使用汉字,也有各自的标准。在中国大陆,字符集的主要发展历程是由GB2312(6763个汉字)到GB13000(20902个汉字)再到GB18030(27533个汉字)
① 汉字编码输入系统信源的统计结构
在讨论语言文字信源的统计结构时,一般都不考虑标点符号。这里讨论汉字信源的统计结构也不考虑非汉字符号。源字母表中的字符可以是单字,也可以是词。汉字信源可以用一个马尔柯夫链(或称离散马尔柯夫过程)来描述。马尔柯夫链的阶可高可低,阶数越高对汉字信源的描述就越准确。在阶数相同时,以词为源字母表中的字符又比以单字为源字母表中的字符准确。但是,越准确的描述需要的运算量就越大。
对于一般汉字输入编码来说,只有单字的零阶熵和词的零阶熵实际意义最大。汉字的最大熵和极限熵也有很大的理论价值。另外两个比较重要的派生指标是汉字信源的相对熵和冗余度。下面我们就这些内容加以讨论。

对于单字的零阶熵,由于出现概率越小的汉字对零阶熵的影响越小,且汉字的概率分布极均匀,所以如果以汉字出现概率的高低收录汉字的话,当字集的大小达到一定程度后,不论汉字数量如何增加,汉字的零阶熵都几乎不再变化。GB2312、GB13000、GB18030三者所收录汉字的数量是递增的,然而所增加的汉字都几乎是低频的汉字,因此GB2312中的汉字也就基本上决定了汉字的零阶熵,字符集的增大对其影响不大。目前学者们对现代汉字零阶熵计算的结果比较一致,大约为9.66比特。
对于单字的零阶熵,由于出现概率越小的汉字对零阶熵的影响越小,且汉字的概率分布极均匀,所以如果以汉字出现概率的高低收录汉字的话,当字集的大小达到一定程度后,不论汉字数量如何增加,汉字的零阶熵都几乎不再变化。GB2312、GB13000、GB18030三者所收录汉字的数量是递增的,然而所增加的汉字都几乎是低频的汉字,因此GB2312中的汉字也就基本上决定了汉字的零阶熵,字符集的增大对其影响不大。目前学者们对现代汉字零阶熵计算的结果比较一致,大约为9.66比特。
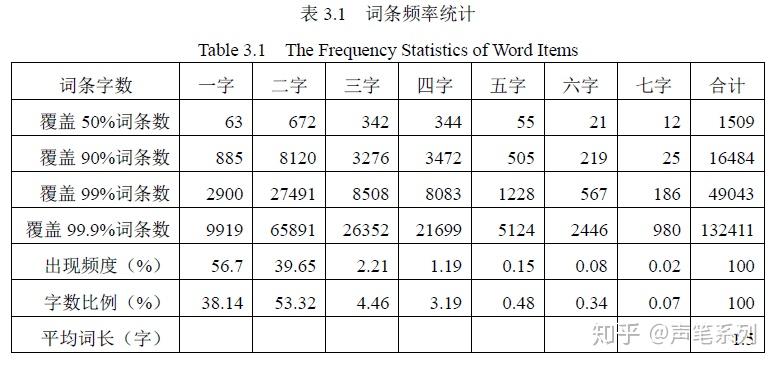
对于词的零阶熵,情况和单字的零阶熵类似,只是计算的规模要大得多。目前,词的零阶熵结果大约是11.46比特/词。根据北京航空航天大学等单位承担的“七五”国家重点科技攻关项目“现代汉语词频统计”所得的结果(参见表3.1),词的平均长度为1.5字。这样,把词的零阶熵折合为汉字熵的结果为11.46/1.5=7.64。
② 输入方式对汉字信源熵率的影响
在“看打”时,输入者产生消息的速度肯定会受到其阅读速度的制约。另外,因输入者打字的熟练程度不同,他还需要不同程度地查看屏幕上提示的反馈信息,这种来回视线转移所造成的字词定位困难会进一步限制他产生消息的速度。越依赖屏幕提示的输入法对“看打”时产生消息的速度影响越大。比如“全拼”就比“五笔字型”对屏幕提示的依赖性大得多,除非能记住重码字词的位置,否则“看打”时效率非常低下。
在“听打”时,汉字信源熵率取决于口述者的说话速度和录入者的听话速度。如果前者超过后者,那么后者就成为速度瓶颈。如果前者慢于后者,那么前者就成为速度瓶颈。一般来讲,口授者是边思维边说话,因此口授者的说话速度又受其思维速度的限制。
在“想打”时,汉字信源熵率主要取决于录入者的思维速度。
无论是“听打”还是“想打”,录入者一般都是注视着插入光标进行操作的,因此在插入光标处或在插入光标附近提供适当的反馈信息可以帮助他减少记忆量,并且不会对信源熵率产生太大的影响。
③ 特定输入者对汉字信源统计结构的影响
上述汉字信源统计结构的结果都是以汉字使用者全体所产生的汉字文本为基础进行统计而得出来的。但是,不同的输入者有不同的知识背景和字词使用习惯。如果统计仅局限于某个输入者所产生的汉字文本,则不同的输入者将会成为具有不同统计结构的信源。为了适应个性化输入的需要,输入法软件应该能够可针对不同用户采用不同的优化编码。进一步,还可以在用户输入不同领域的内容时动态地提供不同的编码,使输入法更具利用特殊场景的能力。