Unicode九个「鼠」,有六个是行书草书,汉字编码专家这样干,外国同行知道吗?社区知道吗?
发布时间:
2024-08-19 02:09
阅读量:
72
外国同行也是这么做的。符号 "&" 足足有 9 个额外的变体[1]!
﹠&⅋ 如果显示的不是九个,说明字体不全。
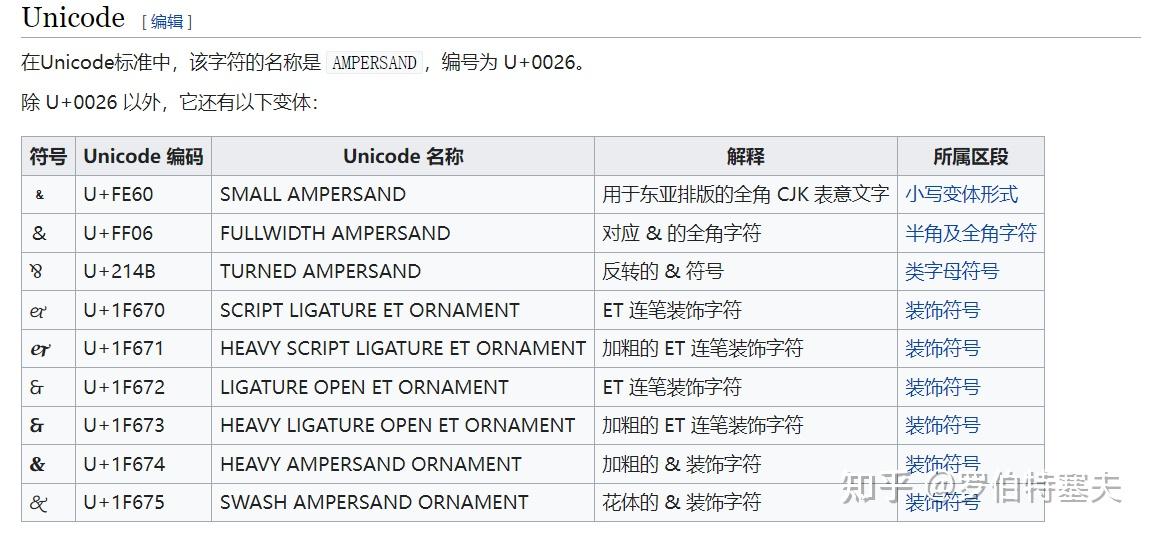
至少社区知道 "&" 符号有10种,还专门把它写到了维基百科里面。
我同意 Unicode 在“字符变体”的处理方面很有问题,但这个问题肯定不是中国人带来的。
更新(跑题):
按编码理论,最常用的字符应该用最短的编码。U+0026在UTF-8当中只占用1字节,考虑到&“还算常用”(而且继承自ASCII),当然无可厚非。但考虑到它的其它9个变体以及这9个变体的使用频率,这9个变体显然占用了过多码位。
我们不妨假设这9个变体都是必要的——这些变体必须写在Unicode里面,而不是通过设计字体或修改字号来实现。那我们为何不设计几个修饰符呢?不难发现,要实现上面9个变体,只需要增加7个修饰符:
- 全角修饰符
- 小字符修饰符
- 反转修饰符
- 花体修饰符1
- 花体修饰符2
- 花体修饰符3
- 加粗修饰符
这样,通过在字符前后加修饰符,我们将9个字符压成了7个修饰符。在编码这9个少见的字符时,我们会用“修饰符+字符”的形式来使用较长的编码。从而使得较短的编码可以由较常用的符号占用。
而且,这些修饰符也可以用于其它字符。以 "@" 字符的变体为例[2]:
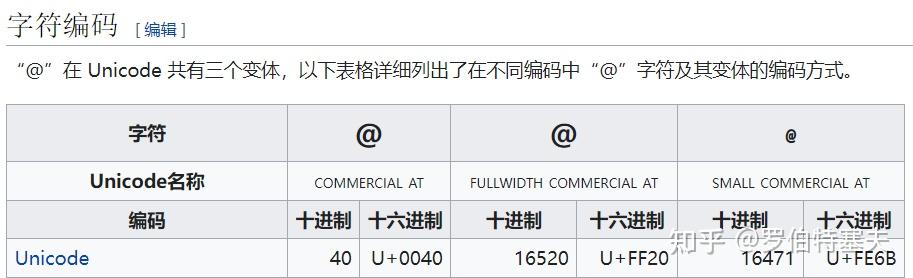
又何必占用这么多码位呢?
END