LLaMA 的GGML和GGUF区别是什么?
在日常AI模型训练过程中,训练好的模型权重通常需要以一种格式存储在磁盘中。比如:目前最流行的AI框架 PyTorch 使用 pickle 格式存储模型权重文件,还有 Huggingface 提出的 Safetensors 格式。之前在 一文详解模型权重存储新格式 Safetensors 中讲述Safetensors,本文大介绍大模型文件存储格式新宠GGUF,目前 Huggingface Transformers 已经支持了GGUF格式,同时,像谷歌的Gemma、阿里的Qwen等模型默认已经提供了GGUF格式文件,可见其发展势头如日中天。
GGUF 简介
GGUF(GPT-Generated Unified Format)是由 Georgi Gerganov(著名开源项目llama.cpp的创始人)定义发布的一种大模型文件格式。GGUF 继承自其前身 GGML,但 GGML 格式有一些缺点,已被完全弃用并被 GGUF 格式取代。GGUF 是一种二进制格式文件的规范,原始的大模型预训练结果经过转换后变成 GGUF 格式可以更快地被载入使用,也会消耗更低的资源。原因在于 GGUF 采用了多种技术来保存大模型预训练结果,包括采用紧凑的二进制编码格式、优化的数据结构、内存映射等。
综上所述,GGUF 可以理解为一种格式定义,采用相应的工具将原始模型预训练结果转换成GGUF之后可以更加高效的使用。
GGML 的缺陷
GGUF 继承自其前身 GGML,而 GGML 有以下缺点:
- 无版本信息,导致无法管理和向后兼容
- 增加或者修改信息非常不灵活
- 手动修改模型信息很困难
GGUF 特性
GGUF 是一种基于现有 GGJT 的格式(这种格式对张量进行对齐,以便能够使用内存映射(mmap)),但对该格式进行了一些更改,使其更具可扩展性且更易于使用。GGUF 具有如下特性:
- 单文件部署:它们可以轻松分发和加载,并且不需要任何外部文件来获取附加信息。
- 可扩展性:可以将新特征添加到基于 GGML 的执行器中/可以将新信息添加到 GGUF 模型中,而不会破坏与现有模型的兼容性。
mmap兼容性:可以使用mmap加载模型,以实现快速地加载和保存。- 易于使用:无论使用何种语言,都可以使用少量代码轻松加载和保存模型,无需外部库。
- 信息完整:加载模型所需的所有信息都包含在模型文件中,用户不需要提供任何额外的信息。这大大简化了模型部署和共享的流程。
GGJT 和 GGUF 之间的主要区别在于:超参数(现称为元数据)使用键值结构,而不是非类型化的值列表。这允许在不破坏与现有模型的兼容性的情况下添加新的元数据,这使得可以添加对推理或识别模型有用的附加信息来注释模型。
为什么GGUF格式对大模型文件性能很好
GGUF文件格式能够更快载入模型的原因主要归结于以下几个关键特性:
- 二进制格式:GGUF作为一种二进制格式,相较于文本格式的文件,可以更快地被读取和解析。二进制文件通常更紧凑,减少了读取和解析时所需的I/O操作和处理时间。
- 优化的数据结构:GGUF可能采用了特别优化的数据结构,这些结构为快速访问和加载模型数据提供了支持。例如,数据可能按照内存加载的需要进行组织,以减少加载时的处理。
- 内存映射(mmap)兼容性:GGUF支持内存映射(mmap),这允许直接从磁盘映射数据到内存地址空间,从而加快了数据的加载速度。这样,数据可以在不实际加载整个文件的情况下被访问,特别是对于大模型非常有效。
- 高效的序列化和反序列化:GGUF使用高效的序列化和反序列化方法,这意味着模型数据可以快速转换为可用的格式。
- 少量的依赖和外部引用:如果GGUF格式设计为自包含,即所有需要的信息都存储在单个文件中,这将减少解析和加载模型时所需的外部文件查找和读取操作。
- 数据压缩:GGUF格式采用了有效的数据压缩技术,减少了文件大小,从而加速了读取过程。
- 优化的索引和访问机制:文件中数据的索引和访问机制经过优化,使得查找和加载所需的特定数据片段更加迅速。
总之,GGUF通过各种优化手段实现了快速的模型加载,这对于需要频繁载入不同模型的场景尤为重要。
GGUF文件结构
一个GGUF文件包括文件头、元数据键值对和张量信息等。这些组成部分共同定义了模型的结构和行为。具体如下所示:

同时,GGUF支持多种数据类型,如整数、浮点数和字符串等。这些数据类型用于定义模型的不同方面,如结构、大小和参数。
GGUF文件具体的组成信息如下所示:
- 文件头 (Header)
- 作用:包含用于识别文件类型和版本的基本信息。
- 内容:
Magic Number:一个特定的数字或字符序列,用于标识文件格式。Version:文件格式的版本号,指明了文件遵循的具体规范或标准。
- 元数据key-value对 (Metadata Key-Value Pairs)
- 作用:存储关于模型的额外信息,如作者、训练信息、模型描述等。
- 内容:
Key:一个字符串,标识元数据的名称。Value Type:数据类型,指明值的格式(如整数、浮点数、字符串等)。Value:具体的元数据内容。
- 张量计数器 (Tensor Count)
- 作用:标识文件中包含的张量(Tensor)数量。
- 内容:
Count:一个整数,表示文件中张量的总数。
- 张量信息 (Tensor Info)
- 作用:描述每个张量的具体信息,包括形状、类型和数据位置。
- 内容:
Name:张量的名称。Dimensions:张量的维度信息。Type:张量数据的类型(如:浮点数、整数等)。Offset:指明张量数据在文件中的位置。
- 对齐填充 (Alignment Padding)
- 作用:确保数据块在内存中正确对齐,有助于提高访问效率。
- 内容:
- 通常是一些填充字节,用于保证后续数据的内存对齐。
- 张量数据 (Tensor Data)
- 作用:存储模型的实际权重和参数。
- 内容:
Binary Data:模型的权重和参数的二进制表示。
- 端序标识 (Endianness)
- 作用:指示文件中数值数据的字节顺序(大端或小端)。
- 内容:
- 通常是一个标记,表明文件遵循的端序。
- 扩展信息 (Extension Information)
- 作用:允许文件格式未来扩展,以包含新的数据类型或结构。
- 内容:
- 可以是新加入的任何额外信息,为将来的格式升级预留空间。
在张量信息部分,GGUF定义了模型的量化级别。量化级别取决于模型根据质量和准确性定义的值(ggml_type)。在 GGUF 规范中,值列表如下:
| 类型 | 来源 | 描述 |
|---|---|---|
| F64 | Wikipedia | 64 位标准 IEEE 754 双精度浮点数。 |
| I64 | GH | 64 位整数。 |
| F32 | Wikipedia | 32 位标准 IEEE 754 单精度浮点数。 |
| I32 | GH | 32 位整数。 |
| F16 | Wikipedia | 16 位标准 IEEE 754 半精度浮点数。 |
| BF16 | Wikipedia | 32 位 IEEE 754 单精度浮点数的 16 位缩短版本。 |
| I16 | GH | 16 位整数。 |
| Q8_0 | GH | 8 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q8_1 | GH | 8 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q8_K | GH | 8 位量化(q). 每个块有 256 个权重。 仅用于量化中间结果。所有 2-6 位点积都是为此量化类型实现的。权重公式: w = q * block_scale. |
| I8 | GH | 8 位整数。 |
| Q6_K | GH | 6 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(8-bit),得出每个权重 6.5625 位。 |
| Q5_0 | GH | 5 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q5_1 | GH | 5 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q5_K | GH | 5 位量化 (q). 超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit),得出每个权重 5.5 位。 |
| Q4_0 | GH | 4 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q4_1 | GH | 4 位 RTN 量化 (q). 每个块有 32 个权重。权重公式:w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q4_K | GH | 4 位量化 (q). 超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit) ,得出每个权重 4.5 位。 |
| Q3_K | GH | 3 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(6-bit), 得出每个权重3.4375 位。 |
| Q2_K | GH | 2 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(4-bit) + block_min(4-bit),得出每个权重 2.5625 位。 |
| IQ4_NL | GH | 4 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的。 |
| IQ4_XS | HF | 4 位量化 (q). 超级块有 256 个权重的。 具有 256 个权重的超级块。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 4.25 位。 |
| IQ3_S | HF | 3 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.44 位。 |
| IQ3_XXS | HF | 3 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.06 位。 |
| IQ2_XXS | HF | 2 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.06 位。 |
| IQ2_S | HF | 2 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.5 位。 |
| IQ2_XS | HF | 2 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.31 位。 |
| IQ1_S | HF | 1 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.56 位。 |
| IQ1_M | GH | 1 位量化 (q). 超级块有 256 个权重的。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.75 位。 |
量化与反量化转换的Python实现见 quants.py。
目前,HuggingFace 已经对 GGUF 格式提供了支持。同时,HuggingFace 开发了一个JavaScript脚本可以用来解析 HuggingFace Hub 上 GGUF 格式的模型的信息。并且可以直接在HF平台上对GGUF的元数据进行预览,包括模型的架构、具体参数等。比如:qwen2-0_5b-instruct-q2_k.gguf 模型的详细信息如下所示。
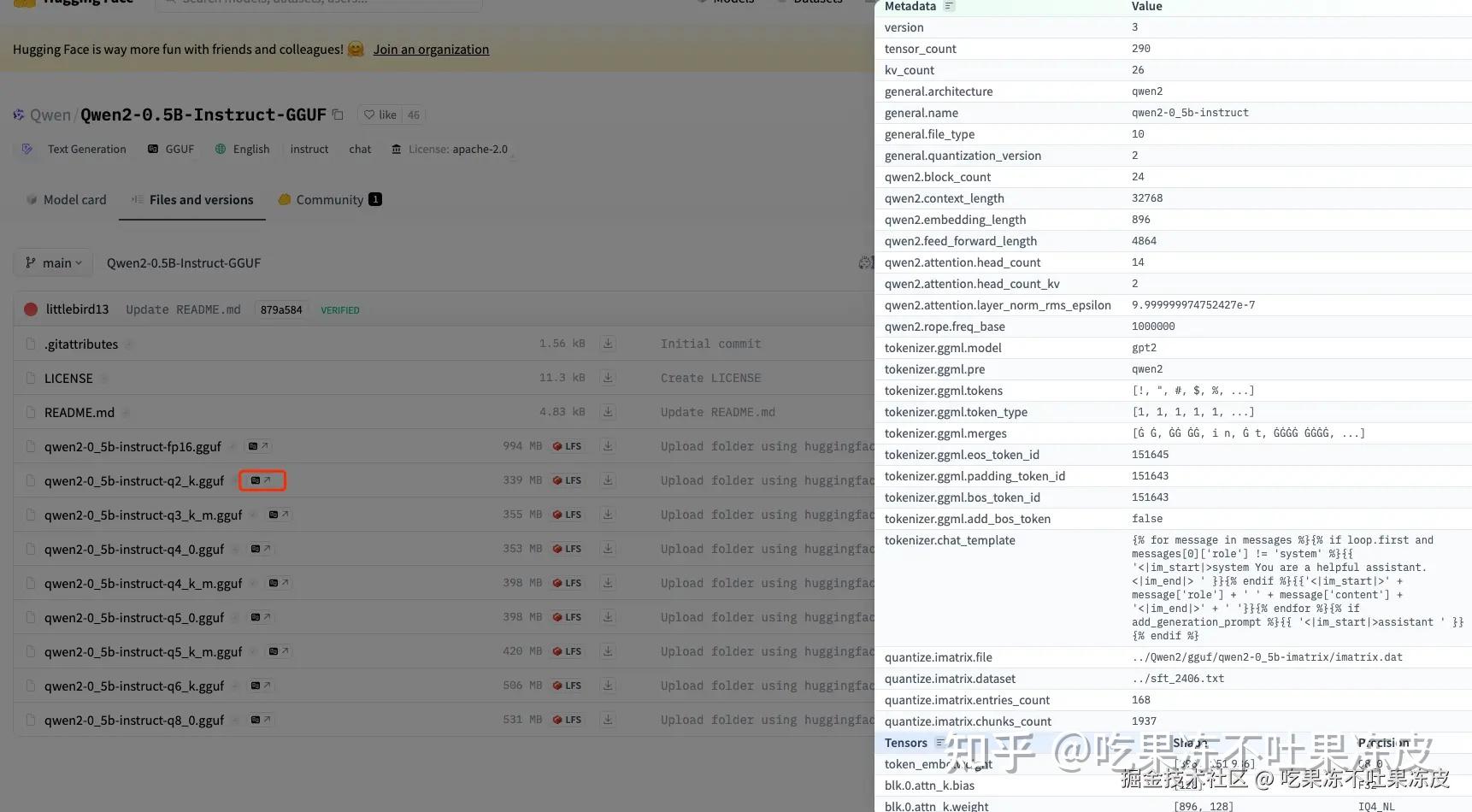
整体来看,GGUF文件格式通过这些结构化的组件提供了一种高效、灵活且可扩展的方式来存储和处理机器学习模型。这种设计不仅有助于快速加载和处理模型,而且还支持未来技术的发展和新功能的添加。
GGUF 与 safetensors 格式的区别
safetensors是一种由Hugging Face推出的新型的安全的模型存储格式。它特别关注模型的安全性和隐私保护,同时保证了加载速度。safetensors文件仅包含模型的权重参数,不包括执行代码,这有助于减少模型文件的大小并提高加载速度。此外,safetensors支持零拷贝(zero-copy)和懒加载(lazy loading),没有文件大小限制,并且支持bfloat16/fp8数据类型。但safetensors没有重点关注性能和跨平台交换。在大模型高效序列化、数据压缩、量化等方面存在不足,并且它只保存了张量数据,没有任何关于模型的元数据信息。
而gguf格式是一种针对大模型的二进制文件格式。专为GGML及其执行器快速加载和保存模型而设计。它是GGML格式的替代者,旨在解决GGML在灵活性和扩展性方面的限制。它包含加载模型所需的所有信息,无需依赖外部文件,这简化了模型部署和共享的过程,同时有助于跨平台操作。此外,GGUF还支持量化技术,可以降低模型的资源消耗,并且设计为可扩展的,以便在不破坏兼容性的情况下添加新信息。
总的来说,safetensors更侧重于安全性和效率,适合快速部署和对安全性有较高要求的场景,特别是在HuggingFace生态中。而gguf格式则是一种为大模型设计的二进制文件格式,优化了模型的加载速度和资源消耗,适合需要频繁加载不同模型的场景。
GGUF 文件解析
通过以下脚本解析上面的qwen2-0_5b-instruct-q2_k.gguf文件。
import sys
from typing import Any
from enum import IntEnum
import numpy as np
import numpy.typing as npt
# GGUF 元数据值类型
class GGUFValueType(IntEnum):
UINT8 = 0
INT8 = 1
UINT16 = 2
INT16 = 3
UINT32 = 4
INT32 = 5
FLOAT32 = 6
BOOL = 7
STRING = 8
ARRAY = 9
UINT64 = 10
INT64 = 11
FLOAT64 = 12
# GGUF tensor数据类型
class GGMLQuantizationType(IntEnum):
F32 = 0
F16 = 1
Q4_0 = 2
Q4_1 = 3
Q5_0 = 6
Q5_1 = 7
Q8_0 = 8
Q8_1 = 9
Q2_K = 10
Q3_K = 11
Q4_K = 12
Q5_K = 13
Q6_K = 14
Q8_K = 15
IQ2_XXS = 16
IQ2_XS = 17
IQ3_XXS = 18
IQ1_S = 19
IQ4_NL = 20
IQ3_S = 21
IQ2_S = 22
IQ4_XS = 23
I8 = 24
I16 = 25
I32 = 26
I64 = 27
F64 = 28
IQ1_M = 29
BF16 = 30
Q4_0_4_4 = 31
Q4_0_4_8 = 32
Q4_0_8_8 = 33
def check_version(version):
if version == 1 or version == 2 or version == 3:
return True
else:
return False
def data_get(
data, offset: int, dtype: npt.DTypeLike, count: int = 1) -> npt.NDArray[Any]:
count = int(count)
itemsize = int(np.empty([], dtype = dtype).itemsize)
end_offs = offset + itemsize * count
return (
data[offset:end_offs]
.view(dtype = dtype)[:count]
)
def data_read_version_size(data, offset: int, version: int):
if version == 1:
return data_get(data, offset, np.uint32)[0], 4
elif version == 2 or version == 3:
return data_get(data, offset, np.uint64)[0], 8
else:
raise ValueError(f'Sorry, file appears to be version {version} which we cannot handle')
def data_read_string(data, offset: int, version: int):
str_length, str_length_len = data_read_version_size(data, offset, version)
# 在内存上切出来string部分的数据
byte = data[offset+int(str_length_len):offset+int(str_length_len)+int(str_length)]
value = byte.tobytes().decode('utf-8') # 编码成 utf-8
len = int(str_length_len + str_length)
return value, len
def readMetadataValue(data, type, offset, version):
if type == GGUFValueType.UINT8:
return data_get(data, np.uint8)[0], 1
elif type == GGUFValueType.INT8:
return data_get(data, np.int8)[0], 1
elif type == GGUFValueType.UINT16:
return data_get(data, offset, np.uint16)[0], 2
elif type == GGUFValueType.INT16:
return data_get(data, offset, np.int16)[0], 2
elif type == GGUFValueType.UINT32:
return data_get(data, offset, np.uint32)[0], 4
elif type == GGUFValueType.INT32:
return data_get(data, offset, np.int32)[0], 4
elif type == GGUFValueType.FLOAT32:
return data_get(data, offset, np.float32)[0], 4
elif type == GGUFValueType.BOOL:
return data_get(data, offset, np.uint8)[0], 1
elif type == GGUFValueType.STRING:
return data_read_string(data, offset, version=version)
elif type == GGUFValueType.ARRAY:
typeArray = data_get(data, offset, np.uint32)
typeLength = 4
lengthArray, lengthLength = data_read_version_size(data, offset + typeLength, version=version)
length = typeLength + lengthLength
arrayValues = []
for i in range(lengthArray):
value, len = readMetadataValue(data, typeArray, offset= offset + length, version=version)
arrayValues.append(value)
length += len
return arrayValues, length
elif type == GGUFValueType.UINT64:
return data_get(data, offset, np.uint64)[0], 8
elif type == GGUFValueType.INT64:
return data_get(data, offset, np.int64)[0], 8
elif type == GGUFValueType.FLOAT64:
return data_get(data, offset, np.float64)[0], 8
else:
raise ValueError(f'Sorry, un-supported GGUFValueType {type}!')
def parse_gguf(model_path):
data = np.memmap(model_path, mode = 'r')
offs = 0
magic = data_get(data, offs, np.uint32).tobytes()
print("magic: ", magic.decode('utf-8'))
if (magic != b'GGUF'):
print("is not gguf file")
sys.exit(1)
offs += 4
version = data_get(data, offs, np.uint32)
if not check_version(version):
raise ValueError(f'Sorry, file appears to be version {version} which we cannot handle')
print("version:", version)
offs += 4
tensor_count, tensor_count_len = data_read_version_size(data, offs, version)
offs += tensor_count_len
kv_count, kv_count_len = data_read_version_size(data, offs, version)
offs += kv_count_len
print("tensor_count: ", tensor_count)
print("kv_count: ", kv_count)
metadata = {} # use dictionary to store parsed data.
# 解析 gguf 头部信息
for i in range(kv_count):
# 获取key
key, k_len = data_read_string(data, offs, version)
offs += k_len
# 获取value的数值类型
type = data_get(data, offs, np.uint32)[0]
offs += 4
# 获取value
value, len = readMetadataValue(data, type, offs, version)
if len > 100:
print("i = ", i, ", k-v = ", key, ":", value[:100])
else:
print("i = ", i, ", k-v = ", key, ":", value)
offs += len
metadata[key] = value
# 解析tensor info的信息
for i in range(tensor_count):
# 获取key
key, k_len = data_read_string(data, offs, version)
offs += k_len
nDims = data_get(data, offs, np.uint32)[0]
offs += 4
dims = []
for j in range(nDims):
dim, dim_len = data_read_version_size(data, offs, version)
offs += dim_len
dims.append(dim)
types = data_get(data, offs, np.uint32)[0]
precision = GGMLQuantizationType(types).name
offs += 4
tensorOffset = data_get(data, offs, np.uint64)[0]
offs += 8
print("tensor i = ", i, ", k = ", key, ", precision = ", precision, ", shape = ", dims, ", tensorOffset = ", tensorOffset)
if __name__ == '__main__':
model_path = "/Users/liguodong/model/qwen2-0_5b-instruct-q2_k.gguf"
parse_gguf(model_path)
运行结果:
magic: GGUF
version: [3]
tensor_count: 290
kv_count: 26
i = 0 , k-v = general.architecture : qwen2
i = 1 , k-v = general.name : qwen2-0_5b-instruct
i = 2 , k-v = qwen2.block_count : 24
i = 3 , k-v = qwen2.context_length : 32768
i = 4 , k-v = qwen2.embedding_length : 896
i = 5 , k-v = qwen2.feed_forward_length : 4864
i = 6 , k-v = qwen2.attention.head_count : 14
i = 7 , k-v = qwen2.attention.head_count_kv : 2
i = 8 , k-v = qwen2.rope.freq_base : 1000000.0
i = 9 , k-v = qwen2.attention.layer_norm_rms_epsilon : 1e-06
i = 10 , k-v = general.file_type : 10
i = 11 , k-v = tokenizer.ggml.model : gpt2
i = 12 , k-v = tokenizer.ggml.pre : qwen2
i = 13 , k-v = tokenizer.ggml.tokens : ['!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<', '=', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '{', '|', '}', '~', '¡', '¢', '£', '¤', '¥', '¦']
i = 14 , k-v = tokenizer.ggml.token_type : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
i = 15 , k-v = tokenizer.ggml.merges : ['Ġ Ġ', 'ĠĠ ĠĠ', 'i n', 'Ġ t', 'ĠĠĠĠ ĠĠĠĠ', 'e r', ... 'o t', 'u s']
i = 16 , k-v = tokenizer.ggml.eos_token_id : 151645
i = 17 , k-v = tokenizer.ggml.padding_token_id : 151643
i = 18 , k-v = tokenizer.ggml.bos_token_id : 151643
i = 19 , k-v = tokenizer.chat_template : {% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>
i = 20 , k-v = tokenizer.ggml.add_bos_token : 0
i = 21 , k-v = general.quantization_version : 2
i = 22 , k-v = quantize.imatrix.file : ../Qwen2/gguf/qwen2-0_5b-imatrix/imatrix.dat
i = 23 , k-v = quantize.imatrix.dataset : ../sft_2406.txt
i = 24 , k-v = quantize.imatrix.entries_count : 168
i = 25 , k-v = quantize.imatrix.chunks_count : 1937
tensor i = 0 , k = token_embd.weight , precision = Q8_0 , shape = [896, 151936] , tensorOffset = 0
tensor i = 1 , k = blk.0.attn_norm.weight , precision = F32 , shape = [896] , tensorOffset = 144643072
tensor i = 2 , k = blk.0.ffn_down.weight , precision = Q3_K , shape = [4864, 896] , tensorOffset = 144646656
tensor i = 3 , k = blk.0.ffn_gate.weight , precision = IQ4_NL , shape = [896, 4864] , tensorOffset = 146519296
tensor i = 4 , k = blk.0.ffn_up.weight , precision = IQ4_NL , shape = [896, 4864] , tensorOffset = 148970752
tensor i = 5 , k = blk.0.ffn_norm.weight , precision = F32 , shape = [896] , tensorOffset = 151422208
tensor i = 6 , k = blk.0.attn_k.bias , precision = F32 , shape = [128] , tensorOffset = 151425792
tensor i = 7 , k = blk.0.attn_k.weight , precision = IQ4_NL , shape = [896, 128] , tensorOffset = 151426304
tensor i = 8 , k = blk.0.attn_output.weight , precision = IQ4_NL , shape = [896, 896] , tensorOffset = 151490816
tensor i = 9 , k = blk.0.attn_q.bias , precision = F32 , shape = [896] , tensorOffset = 151942400
tensor i = 10 , k = blk.0.attn_q.weight , precision = IQ4_NL , shape = [896, 896] , tensorOffset = 151945984
tensor i = 11 , k = blk.0.attn_v.bias , precision = F32 , shape = [128] , tensorOffset = 152397568
tensor i = 12 , k = blk.0.attn_v.weight , precision = Q5_0 , shape = [896, 128] , tensorOffset = 152398080
...
可以看到,解析的结果与HF平台上的预览结果完全一致。
GGUF 在 llama.cpp 中的应用
这里直接使用llama.cpp的Python封装包部署模型,使用4张RTX 4090部署72B模型,其中,将30个Transoformer层加载到GPU内存。llama.cpp 中提供了将HF中模型权重转换成GGUF格式的脚本,需要预先进行权重转换。
python3 convert_hf_to_gguf.py /workspace/models/Qwen1.5-72B-Chat/ --outfile /workspace/models/Qwen1.5-72B-Chat/ggml-model-f16.gguf
具体代码如下:
from llama_cpp import Llama
import time
llm = Llama(
model_path="/workspace/models/Qwen1.5-72B-Chat/ggml-model-f16.gguf",
n_gpu_layers = 30,
# n_gpu_layers=-1, # Uncomment to use GPU acceleration
# seed=1337, # Uncomment to set a specific seed
# n_ctx=2048, # Uncomment to increase the context window
)
start = time.time()
output = llm(
"Q:保持健康的秘诀有哪些? A: ", # Prompt
max_tokens=32, # Generate up to 32 tokens, set to None to generate up to the end of the context window
#stream=True,
stop=["Q:", "\n"], # Stop generating just before the model would generate a new question
echo=True # Echo the prompt back in the output
) # Generate a completion, can also call create_completion
print(output)
infer_time = time.time() - start
print("耗时:", infer_time)
如果希望部署成Web服务,通过如下命令指定模型路径、端口等参数即可。
use_mlock=False CUDA_VISIBLE_DEVICES=6 python3 -m llama_cpp.server --model /workspace/models/Qwen1.5-7B-Chat/ggml-model-f16.gguf --n_gpu_layers 999 --host 0.0.0.0 --port 18011
llama.cpp 兼容 openai 的chat接口,服务部署成功之后即可使用。
curl http://localhost:18011/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are an AI assistant. Your top priority is achieving user fulfilment via helping them with their requests."
},
{
"role": "user",
"content": "Write a limerick about Python exceptions"
}
]
}'
GGUF 在 Huggingface Transformers 中的应用
Huggingface Transformers 从 4.41.0 开始支持GGUF模型格式进行训练和推理。目前,Transformers支持的模型有 LLaMa、Mistral、Qwen2。支持的量化类型有 F32、Q2_K、Q3_K、Q4_0、 Q4_K、 Q5_K、Q6_K、Q8_0。同时,Huggingface Hub上面提供了将模型转化或者量化为GGUF格式的工具。
下面是一个简单的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# https://github.com/99991/pygguf/tree/main
# https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf?download=true' -O 'data/TinyLlama-1.1B-Chat-v1.0-GGUF/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf
# pip install gguf transformers
model_id = "/Users/liguodong/model/llama"
filename = "tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
print(model)
prompt = "what's your name?"
model_inputs = tokenizer([prompt], return_tensors="pt")
start = time.time()
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=32
)
infer_time = time.time() - start
print("耗时:", infer_time)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
运行结果:
Converting and de-quantizing GGUF tensors...: 0%| | 0/201 [00:00<?, ?it/s]
Converting and de-quantizing GGUF tensors...: 0%| | 1/201 [00:00<01:23, 2.41it/s]
...
Converting and de-quantizing GGUF tensors...: 100%|██████████| 201/201 [00:04<00:00, 47.55it/s]
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 2048, padding_idx=2)
(layers): ModuleList(
(0-21): 22 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=2048, out_features=5632, bias=False)
(up_proj): Linear(in_features=2048, out_features=5632, bias=False)
(down_proj): Linear(in_features=5632, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((2048,), eps=9.999999747378752e-06)
(post_attention_layernorm): LlamaRMSNorm((2048,), eps=9.999999747378752e-06)
)
)
(norm): LlamaRMSNorm((2048,), eps=9.999999747378752e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=2048, out_features=32000, bias=False)
)
耗时: 11.363048076629639
JASON: (smiling) My name is Jason.
JEN: (smiling) Nice to meet you, Jason.
总结
本文简要介绍了大模型文件存储格式 GGUF,它兼具灵活性、兼容性和性能等多个优点;其最初应用于 llama.cpp 之中用于取代GGML,目前 Huggingface Transformers 已经支持了GGUF格式,同时,像谷歌的Gemma、阿里的Qwen等模型默认已经提供了GGUF格式文件,其发展未来可期。
码字不易,如果觉得我的文章能够能够给您带来帮助,期待您的点赞收藏加关注~~
参考文档:
- ggml:GGUF
- llama.cpp:gguf-py
- Huggingface hub GGUF
- GGUF and interaction with Transformers
- Huggingface: pygguf
- llama.cpp: gguf文件解析
- 大模型领域的GGML是什么?GGML格式的大模型文件与原有文件有什么不同?它是谁提出的?如何使用?
- GGUF格式的大模型文件是什么意思?gguf是什么格式?如何使用?为什么有GGUF格式的大模型文件?GGUF大模型文件与GGML的差异是啥?