如何构建条件生成对抗网络(cGAN)?
一、CGAN的定义及其与GAN的区别
CGAN(Conditional Generative Advsersarial Network),即条件生成对抗神经网络。是一种深度学习神经网络,是GAN(生成对抗神经网络)的一种变体。其与GAN的区别在于,GAN是能够生成与真实输入数据具有相似特征的数据,但至于GAN生成的是哪种类别的图片,无法进行具体的限定。比如我们用于训练的数据是{猫,狗,鱼,熊猫,狮子}等动物图片,但如果我们随机丢一串噪声信号序列给训练好的生成器模型,得到的图片仅仅是与这些动物的逼真图像,但具体是哪一类的动物,生成器无法控制。
而CGAN则适用于需要条件控制的生成任务。例如,在图像生成中,可以根据条件信息生成特定风格或特定类别的图片;在文本生成中,可以根据条件信息生成特定主题的文本。仍然以生成动物图片为例,CGAN可以根据我们输入的特定标签,比如我们想要得到一组猫的图片,其可以根据我们的指令生成一系列猫,而不是狗或者熊猫的图片。即,CGAN相比于GAN,区别在于生成器和判别器的输入中加入了额外的条件信息,使得模型能够更加灵活地控制生成样本的特性,适用于更多需要条件控制的生成任务。
二、基本原理和结构
CGAN作为GAN的一种变体,其基本原理和结构与GAN类似,只是在GAN的基础上添加了标签。因此,我们从GAN的结构入手,进行原理上的分析和说明。
2.1 GAN的原理和结构
一个GAN由两个一起训练的网络组成:生成器(Generator)和判别器(Discriminator),这里就以G和D符号进行代替。对于训练好的GAN网络模型,我们肯定是希望给定随机值(潜在输入-通常为符合某种分布的噪声信号)向量作为输入,G可生成与训练数据具有相同结构或特征分布的数据;而对于D,我们训练的最终目标是:给定包含来自训练数据样本和来自G的生成数据样本,D可以将真实的训练样本和虚假的生成样本判别为”真实值“和”生成值(虚假值)“。GAN的神经网络结构如下:
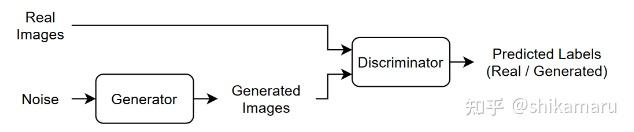
训练GAN的最终目标可以用如下示意图来进行说明:
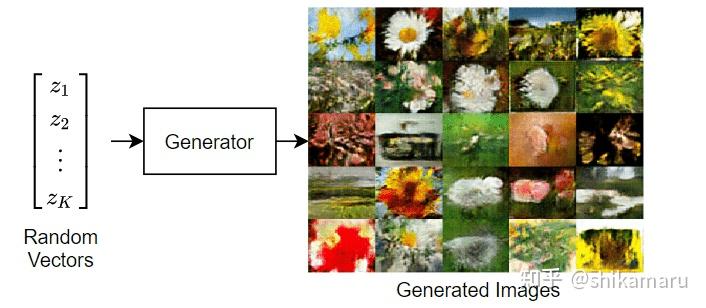
训练GAN的过程,是同时训练G和D两个网络,以使两个网络性能达到最优。即,训练G以生成足够”以假乱真“的数据,可以使D能够将生成数据也判别为真;训练D,使其无论G训练的多好,都可以区分真实数据和G生成的数据,两者通过对抗训练的方式互相博弈,不断迭代优化,最终达到生成高质量样本的目标。
2.2 CGAN的原理和结构
上文说到,CGAN与GAN的区别,就在于CGAN的条件性,可以根据我们的条件,生成对应类型的高质量样本。其G和D的网络结构,相比于GAN,都增加了Label(条件)。其网络结构如下:
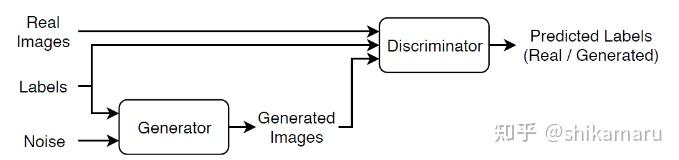
训练CGAN的过程,同样是G和D两个网络通过对抗训练迭代优化,最终达到生成带标签的高质量样本的目标。理想情况下,可以得到一个能够生成对应标签的足够逼真的样本数据的G,以及学习到带标签的训练数据样本特征分布的D。下面就从MATLAB代码的角度,以具体的例子,对该网络的搭建以及训练和测试验证进行解析。
三、MATLAB代码案例及相关代码解析
3.1 训练数据加载
这里以大量种类的花作为数据样本,首先下载并提取Flowers数据集(该数据样本无需自己收集,可以用网络上的开源数据集)。如需要用特定需求的数据集,自行替换加载即可。
url = "http://download.tensorflow.org/example_images/flower_photos.tgz";
downloadFolder = tempdir;
filename = fullfile(downloadFolder,"flower_dataset.tgz");
imageFolder = fullfile(downloadFolder,"flower_photos");
if ~exist(imageFolder,"dir")
disp("Downloading Flowers data set (218 MB)...")
websave(filename,url);
untar(filename,downloadFolder)
end
查看训练样本数据中花的种类数:
classes = categories(imds.Labels);
numClasses = numel(classes) %%用到的花为5类
创建花卉图像数据库,并对训练数据样本进行数据增强(当数据样本量不够时,可用的一些数据增强方法有:传统的基于图像处理的方法,如翻转、旋转、缩放、平移、裁剪、颜色变换、噪声添加、模糊和仿射变换等),这里使用的方法为随机水平翻转的方法;
datasetFolder = fullfile(imageFolder);
imds = imageDatastore(datasetFolder,IncludeSubfolders=true,LabelSource="foldernames");
3.2 网络搭建
训练数据收集完毕后,就着手于网络模型的搭建。CGAN的网络模型分为G(生成器)和D(判别器)。
3.2.1 定义生成器网络
G的网络架构如下:
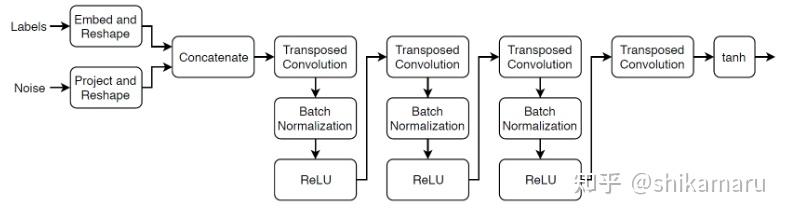
Labels为我们指定的样本标签,Noise为符合任意分布的噪声数据。这里的符合任意分布的噪声向量数据的维度大小为100,可以表征为一维向量: ;类别标签Labels用维度大小为50的嵌入向量(Embedding vector)表示为:
;
该G网络架构的构造原理如下:
- Embed and Reshape模块:将输入噪声向量N重构为一个
的矩阵;(MATLAB中对于CNN的输入数据格式定义为:[样本数,图像宽度,图像高度,图像通道数]-MATLAB的输入数据格式与Pytorch中不同)
- Project and Reshape模块:将类别标签对应的嵌入式向量EnV重构为一个
的矩阵;
- Concatenate模块:将Labels与Noise数据重构后的矩阵按照通道(第三维度)进行整合,得到维度为
的矩阵;
- Transposed Convolution模块:将上述经过整合得到的矩阵经过转置卷积得到上采样矩阵,矩阵维度为
;每层转置卷积神经网络所用的卷积核大小为
,且每层转置卷积所用的卷积核数量随着层数的增加逐渐减小,每层的Stride=2,转置卷积神经网络的输出采用"same”方式的cropping;对于最后一层的转置卷积神经网络,因为该生成器(G)需要生成类似真实的图像,即该网络的输出为
,卷积核数量为3(对应输出图像的RGB通道数为3);
- Batch Normalization和ReLU模块:转置卷积操作后,对数据进行批量归一化和非线性激活函数操作;
- 最后一层的非线性激活函数为tanh函数,输出的图像数据均在
之间;
关于转置卷积神经网络的输入输出图像维度的计算关系如下:
转置卷积是深度学习中常用操作之一,可以将输入数据通过反向运算得到更大尺寸的输出。转置卷积的输出尺寸可以通过以下公式计算:
为输入图像尺寸,
为卷积核移动步长,
为卷积核大小,
为输出图像两边的填充长度;该公式可以看作卷积神经网络输入输出图像尺寸的计算反过程;
若TransposedConvolutionLayer的参数 为
,则MATLAB自动对输出图像尺寸进行裁剪,输出图像尺寸的计算公式为:
;
MATLAB中构造该G网络的代码如下:
numLatentInputs = 100;
embeddingDimension = 50;
numFilters = 64;
filterSize = 5;
projectionSize = [4 4 1024];
netG = dlnetwork;
%%定义由Noise向量生成三维输出图像的转置卷积网络层
layers = [
featureInputLayer(numLatentInputs)
fullyConnectedLayer(prod(projectionSize))
functionLayer(@(X) feature2image(X,projectionSize),Formattable=true)
concatenationLayer(3,2,Name="cat");
transposedConv2dLayer(filterSize,4*numFilters)
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,2*numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,3,Stride=2,Cropping="same")
tanhLayer];
netG = addLayers(netG,layers);
%%定义由Labels向量生成的输入数据
layers = [
featureInputLayer(1)
embeddingLayer(embeddingDimension,numClasses)
fullyConnectedLayer(prod(projectionSize(1:2)))
functionLayer(@(X) feature2image(X,[projectionSize(1:2) 1]),Formattable=true,Name="emb_reshape")];
netG = addLayers(netG,layers);
netG = connectLayers(netG,"emb_reshape","cat/in2");
定义生成器网络后,对G进行初始化:
netG = initialize(netG)
初始化的G性质如下:

3.2.2 定义判别器网络
CGAN的D网络相比于GAN,不仅需要对生成图像和真实图像进行判别,同时还需要判断生成的图像是否符合标签;D的网络架构如下:
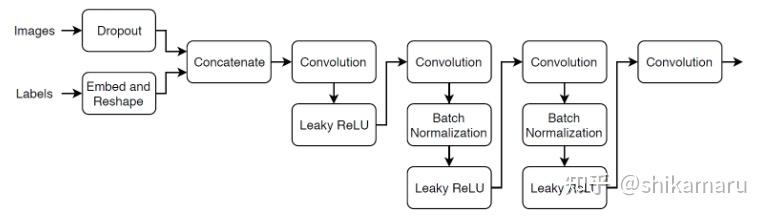
D的输入为图像数据和标签,这里的图像数据包括真实图像和G生成的图像;标签为真实图像与生成图像分别对应的标签;图像数据的维度大小为 ,D的输出为一个标量的类别判别分数;
D的构造原理如下:
- Dropout模块:用于对图像数据添加噪声,并且以一定的概率随机对输入数据设置为0;
- ConvolutionLayer模块:卷积神经网络,对图像数据与标签整合后的样本进行下采样,最终得到对图像数据的判别分数(判定为真或假的分数);卷积核大小为
为2,
属性设置为
,则图像输出维度与输入维度之间的计算关系式如下:
;最后的卷积核大小为
,卷积核数量为1;
- Leaky ReLU模块:非线性激活函数;
MATLAB中构造D网络的代码如下:
dropoutProb = 0.75;
numFilters = 64;
scale = 0.2;
inputSize = [64 64 3];
filterSize = 5;
netD = dlnetwork;
layers = [
imageInputLayer(inputSize,Normalization="none")
dropoutLayer(dropoutProb)
concatenationLayer(3,2,Name="cat")
convolution2dLayer(filterSize,numFilters,Stride=2,Padding="same")
leakyReluLayer(scale)
convolution2dLayer(filterSize,2*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,4*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,8*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(4,1)];
netD = addLayers(netD,layers);
layers = [
featureInputLayer(1)
embeddingLayer(embeddingDimension,numClasses)
fullyConnectedLayer(prod(inputSize(1:2)))
functionLayer(@(X) feature2image(X,[inputSize(1:2) 1]),Formattable=true,Name="emb_reshape")];
netD = addLayers(netD,layers);
netD = connectLayers(netD,"emb_reshape","cat/in2");
初始化D网络:
netD = initialize(netD)
3.2.3 定义模型损失函数
损失函数modelLoss将生成器和判别器netG和netD,小批量输入数据 、数据对应的标签T和一组随机值Z作为输入,并返回损失相对于网络中可学习参数、生成器状态和网络分数的梯度。
MATLAB中代码如下:
function [lossG,lossD,gradientsG,gradientsD,stateG,scoreG,scoreD] = ...
modelLoss(netG,netD,X,T,Z,flipFactor)
% Calculate the predictions for real data with the discriminator network.
YReal = forward(netD,X,T);
% Calculate the predictions for generated data with the discriminator network.
[XGenerated,stateG] = forward(netG,Z,T);
YGenerated = forward(netD,XGenerated,T);
% Calculate probabilities.
probGenerated = sigmoid(YGenerated);
probReal = sigmoid(YReal);
% Calculate the generator and discriminator scores.
scoreG = mean(probGenerated);
scoreD = (mean(probReal) + mean(1-probGenerated)) / 2;
% Flip labels.
numObservations = size(YReal,4);
idx = randperm(numObservations,floor(flipFactor * numObservations));
probReal(:,:,:,idx) = 1 - probReal(:,:,:,idx);
% Calculate the GAN loss.
[lossG, lossD] = ganLoss(probReal,probGenerated);
% For each network, calculate the gradients with respect to the loss.
gradientsG = dlgradient(lossG,netG.Learnables,RetainData=true);
gradientsD = dlgradient(lossD,netD.Learnables);
end
modelLoss的计算中需要用到ganLoss函数,ganLoss函数作为对CGAN的模型权重参数更新的一个目标函数,其目的是为了同时训练G网络和D网络,使两者通过对网络权重参数的不断学习更新,最终达到最优性能。即G网络可以生成足够逼真的图片,可以被判别器判断为真;而D网络需要有足够强的判别真实图片和虚假图片的能力。
假设D网络的输出结果为 ,经过sigmoid函数操作后的值为
,则:
为D网络将输入图片判别为真实图片的概率;而
为D网络将输入图片判别为生成图片(虚假图片)的概率;
因此,对于G网络,其损失函数就需要朝着能使其尽可能生成"骗过"D网络的图片这一目标去设计,即最小化负对数似然函数: ,
为D网络将生成图片判别为真的概率;
对于D网络,其损失函数就需要朝着能尽可能分辨真实图片和生成图片这一目标去设计,即:
MATLAB中对于ganLoss函数的代码定义如下:
function [lossG, lossD] = ganLoss(scoresReal,scoresGenerated)
% Calculate losses for the discriminator network.
lossGenerated = -mean(log(1 - scoresGenerated));
lossReal = -mean(log(scoresReal));
% Combine the losses for the discriminator network.
lossD = lossReal + lossGenerated;
% Calculate the loss for the generator network.
lossG = -mean(log(scoresGenerated));
end
3.2.4 定义模型训练所用超参数
numEpochs = 500; %%训练轮数
miniBatchSize = 128; %%批数据量
learnRate = 0.0002; %%学习率
gradientDecayFactor = 0.5; %%梯度下降因子(用于Adam优化器)
squaredGradientDecayFactor = 0.999; %%用于Adam优化器参数
validationFrequency = 100; %%每100次迭代更新训练过程
flipFactor = 0.5; %%随机翻转一部分真实图像标签的概率
numEpochs = 500; %%训练轮数
miniBatchSize = 128; %%批数据量
learnRate = 0.0002; %%学习率
gradientDecayFactor = 0.5; %%梯度下降因子(用于Adam优化器)
squaredGradientDecayFactor = 0.999; %%用于Adam优化器参数
validationFrequency = 100; %%每100次迭代更新训练过程
flipFactor = 0.5; %%随机翻转一部分真实图像标签的概率
3.2.5 训练模型
- 本例使用自定义训练循环训练模型。循环训练数据,并在每次迭代时更新网络参数。为了监控训练进度,使用随机值数组显示一批生成的图像,并将其输入G网络和D网络。
- 使用minibatchqueue在训练期间处理和管理图像的小批量。对于每个小批量:
- 使用自定义小批量预处理函数preprocessMiniBatch在[-1,1]范围内重新缩放图像;
- 丢弃观察值少于128的任何部分小批量;使用尺寸标签“SSCB”(空间、空间、通道、批次)格式化图像数据;
- 使用尺寸标签“BC”(批次、通道)格式化标签数据;
- 如果GPU可用,请在GPU上进行训练。当minibatchqueue的OutputEnvironment选项为“auto”时,如果GPU可用,minibatchqueue会将每个输出转换为gpuArray;默认情况下,minibatchqueue对象将数据转换为基础类型为single的dlarray对象。
augimds.MiniBatchSize = miniBatchSize;
executionEnvironment = "auto";
mbq = minibatchqueue(augimds, ...
MiniBatchSize=miniBatchSize, ...
PartialMiniBatch="discard", ...
MiniBatchFcn=@preprocessData, ...
MiniBatchFormat=["SSCB" "BC"], ...
OutputEnvironment=executionEnvironment);
初始化Adam优化器的参数:
velocityD = [];
trailingAvgG = [];
trailingAvgSqG = [];
trailingAvgD = [];
trailingAvgSqD = [];
numValidationImagesPerClass = 5;
ZValidation = randn(numLatentInputs,numValidationImagesPerClass*numClasses,"single");
TValidation = single(repmat(1:numClasses,[1 numValidationImagesPerClass]));
ZValidation = dlarray(ZValidation,"CB");
TValidation = dlarray(TValidation,"CB");
if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu"
ZValidation = gpuArray(ZValidation);
TValidation = gpuArray(TValidation);
end
numObservationsTrain = numel(imds.Files);
numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize);
numIterations = numEpochs * numIterationsPerEpoch;
monitor = trainingProgressMonitor( ...
Metrics=["GeneratorScore","DiscriminatorScore"], ...
Info=["Epoch","Iteration"], ...
XLabel="Iteration");
groupSubPlot(monitor,Score=["GeneratorScore","DiscriminatorScore"])
开始训练模型:
epoch = 0;
iteration = 0;
% Loop over epochs.
while epoch < numEpochs && ~monitor.Stop
epoch = epoch + 1;
% Reset and shuffle data.
shuffle(mbq);
% Loop over mini-batches.
while hasdata(mbq) && ~monitor.Stop
iteration = iteration + 1;
% Read mini-batch of data.
[X,T] = next(mbq);
% Generate latent inputs for the generator network. Convert to
% dlarray and specify the dimension labels "CB" (channel, batch).
% If training on a GPU, then convert latent inputs to gpuArray.
Z = randn(numLatentInputs,miniBatchSize,"single");
Z = dlarray(Z,"CB");
if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu"
Z = gpuArray(Z);
end
% Evaluate the gradients of the loss with respect to the learnable
% parameters, the generator state, and the network scores using
% dlfeval and the modelLoss function.
[~,~,gradientsG,gradientsD,stateG,scoreG,scoreD] = ...
dlfeval(@modelLoss,netG,netD,X,T,Z,flipFactor);
netG.State = stateG;
% Update the discriminator network parameters.
[netD,trailingAvgD,trailingAvgSqD] = adamupdate(netD, gradientsD, ...
trailingAvgD, trailingAvgSqD, iteration, ...
learnRate, gradientDecayFactor, squaredGradientDecayFactor);
% Update the generator network parameters.
[netG,trailingAvgG,trailingAvgSqG] = ...
adamupdate(netG, gradientsG, ...
trailingAvgG, trailingAvgSqG, iteration, ...
learnRate, gradientDecayFactor, squaredGradientDecayFactor);
% Every validationFrequency iterations, display batch of generated images using the
% held-out generator input.
if mod(iteration,validationFrequency) == 0 || iteration == 1
% Generate images using the held-out generator input.
XGeneratedValidation = predict(netG,ZValidation,TValidation);
% Tile and rescale the images in the range [0 1].
I = imtile(extractdata(XGeneratedValidation), ...
GridSize=[numValidationImagesPerClass numClasses]);
I = rescale(I);
% Display the images.
image(I)
xticklabels([]);
yticklabels([]);
title("Generated Images");
end
% Update the training progress monitor.
recordMetrics(monitor,iteration, ...
GeneratorScore=scoreG, ...
DiscriminatorScore=scoreD);
updateInfo(monitor,Epoch=epoch,Iteration=iteration);
monitor.Progress = 100*iteration/numIterations;
end
end
模型训练过程中的损失函数曲线和中间过程量的一些生成图片样本如下:
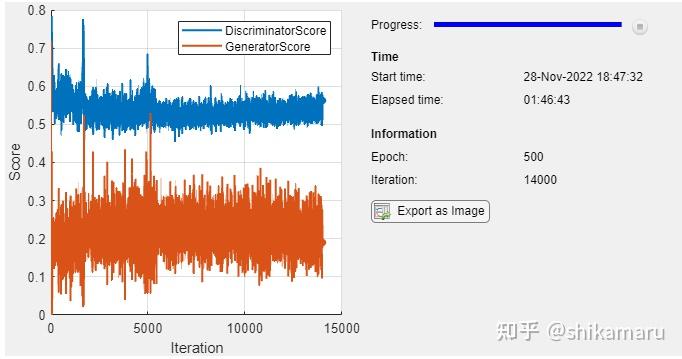

训练完毕的CGAN,其G网络可以用于生成指定标签的图片,生成结果如下:

四、总结
CGAN与GAN的区别就在于是否引入了条件信息。
- GAN是一个无监督学习模型,通过两个模型——生成器(G)和判别器(D)的对抗过程来学习数据的分布。生成器的目标是生成尽可能接近真实数据的样本,而判别器的目标是区分真实样本和生成样本。GAN通过不断迭代训练,最终生成器能够生成以假乱真的数据。而CGAN在GAN的基础上引入了条件信息,这些条件可以是类别标签、文本或其他辅助信息。生成器和判别器的输入都包含这些条件信息,使得生成器能够根据这些条件生成特定类型的数据,而判别器则负责区分真实数据和生成数据是否符合这些条件。
- GAN适用于需要生成大量但不需要特定条件的数据场景,如图像生成、文本生成等;而CGAN适用于需要生成特定类型数据的应用场景,如根据类别标签生成特定类别的图像、根据文本描述生成对应的图像等;
- GAN生成器和判别器都只接收随机噪声作为输入,通过不断迭代训练来学习数据的分布;而CGAN生成器和判别器的输入都包含条件信息,使得生成器能够根据这些条件生成特定类型的数据。
- GAN优点是模型简单,训练过程直观;缺点是生成的样本缺乏多样性,难以控制生成的样本类型;而CGAN优点是能够根据条件信息生成特定类型的数据,生成的样本质量更高;缺点是模型复杂度较高,训练难度较大;
综上所述,CGAN通过引入条件信息,使得生成的数据更加可控和有用,适用于需要生成特定类型数据的场景。而GAN则适用于需要大量生成数据但不需要特定条件的场景。
五、参考链接
文中所用代码均来自于MATLAB官网的CGAN代码,链接如下:Train Conditional Generative Adversarial Network (CGAN)
GAN的原理及代码参考可参考链接:Train Generative Adversarial Network (GAN)