如何看待“燕冬萍事件”?
这个问题非常经典,其实就是“全女回声室”的一个演化典型——一旦你的方向和回声室中的共识相悖,那么就会付出惨重代价。成鸿宇的遭遇就是最典型的一个案例。
以及,根据目前的形势,“某个性别+武力=某个性别+违反世俗意义上的规则”这一公式很快将会再度验证。


首先,我们将这几年的事件联系起来,从目前在这方面的海量例子中,我们能得出一个初步结论:回声室目前的共识是“有男不帮”。
然后,关于回声室,我们可以看看New Media & Society在2024年6月的这篇文章,里面说的是回声室之间声音的关系。
社交网络里,已经开发出了大量用于衡量网络隔离和极化程度的指标。如何衡量意见领袖关注者的同质性呢?可以使用以下公式:
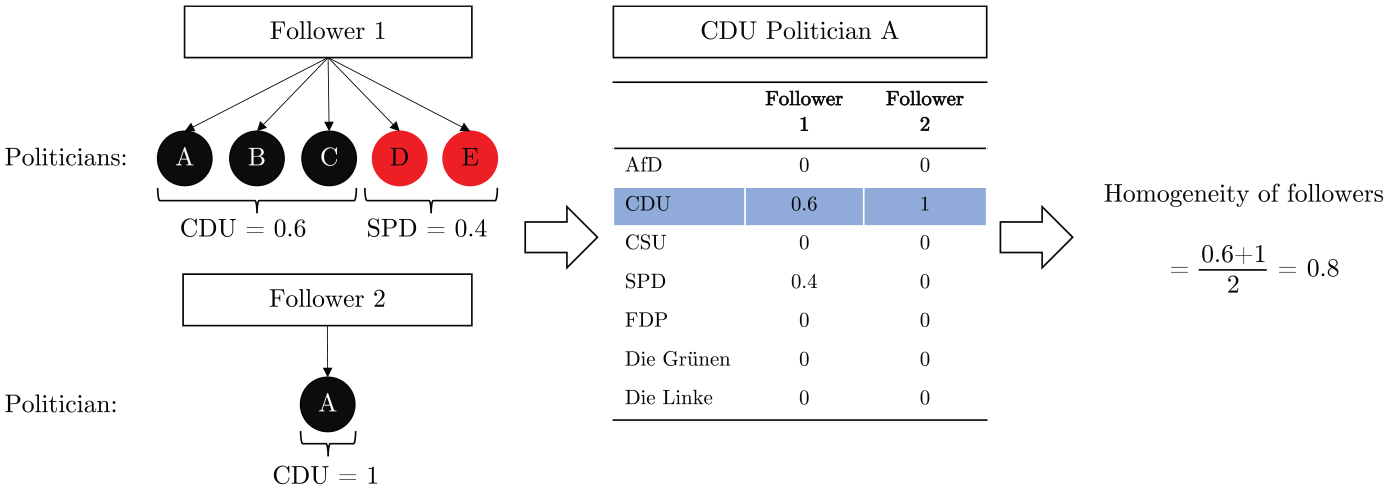
唔姆,如图所示,以上是为直观起见提供的例子。在这里,关注者1关注了来自两个集群的五位意见领袖(A、B、C、D、E):(D 和 E)和(A、B、C)。她与两个集群的联系份额分别为 0.4 和 0.6。另一位用户,关注者2,只关注A。转向A,她被两个关注者关注,没有其他人关注。因此,她的同质性度量等于她的关注者与她所属政党的联系的平均份额:(0.6+1.2)/2=0.8。这表明,在所有意见领袖中,该意见领袖的平均追随者 80% 的联系人都只追随该意见领袖自己。
实验于2018 年 10 月收集了中 462 名活跃在Twitter 上的的意见领袖的178万名粉丝的数据。利用他们与联邦议院的540万个联系,实施了同质性测量。
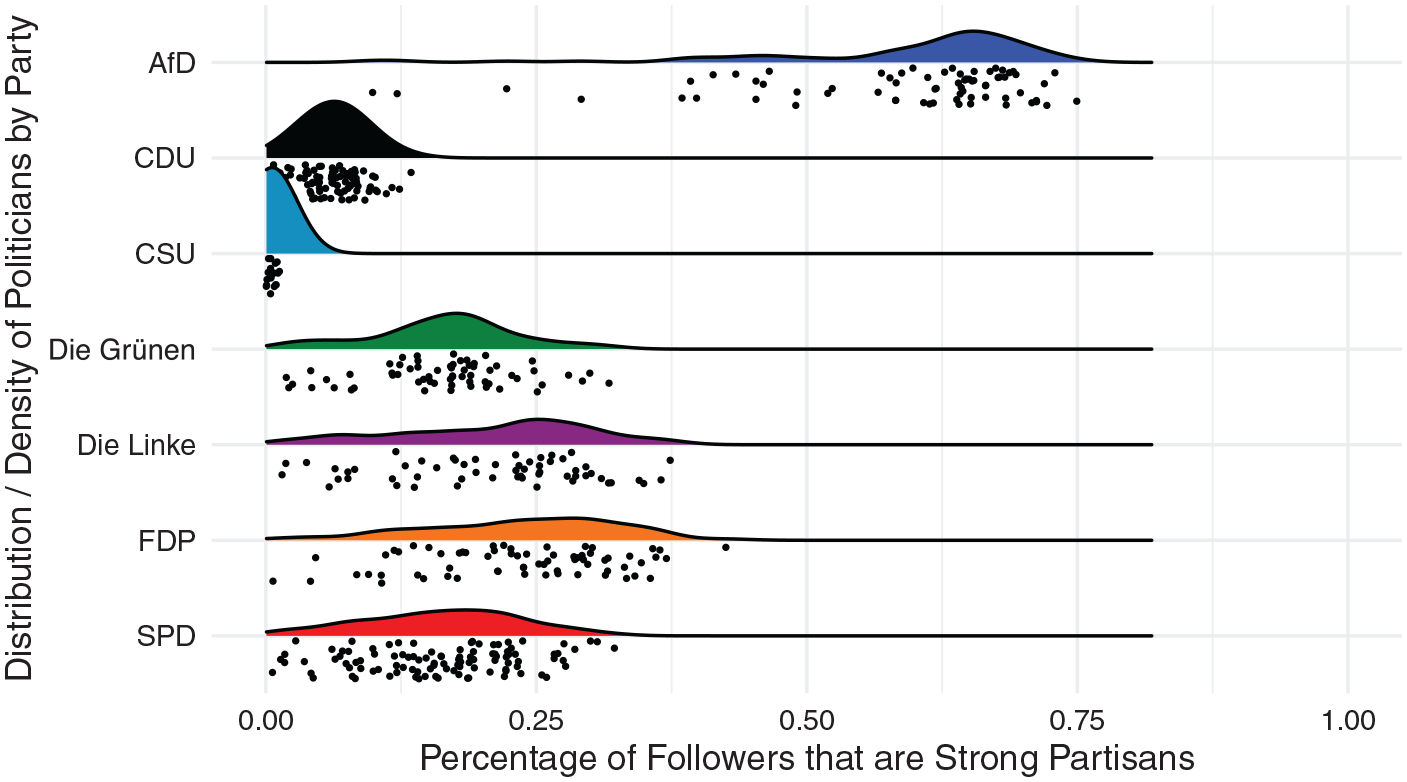
唔姆,如图所示,以上是各集群意见领袖的追随者中坚定关注者的百分比。该图显示了各集群意见领袖坚定关注者所占比例的密度估计值。结论很明显,该图证明了AfD,一个偏向保守的集群的高网络同质性水平,显示坚定的关注者占大多数AfD关注者的55%到75%,而在其他集群中,他们所占的比例要低得多。[1]
什么是坚定关注者呢?举个例子,如果你只关注了思辩,没有关注其他人,每天24小时盯着主页刷新,认定“温柔的思辩姐姐是樱小路露娜”,那么就是一个坚定关注者,如果你不只关注了思辩,而且关注了其他人,那么恭喜你,你“有自己的生活”,而不是一味盲从我。
回到这个问题,有没有证据,证明法院里这群人的倾向呢?我认为是有的,最经典的一个例子如下:
怎么看待最近很火的美国路易吉事件?这件事在大洋彼岸的镜像版,其实就是我要举的例子。
那么,为什么在该类回声室中,形成了“有男不帮”的极强共识呢?
我们可以看看Information Sciences在2023年4月的这篇文章,里面说的是将标签传播算法引入传统的意见动力学模型Hegselmann-Krause中,去说明社区内部信息和最终结构的关系。
什么是Hegselmann-Krause模型呢?
从心理学角度看,个体的观点只会受到其置信阈值内的观点的影响。基于此理论,研究者提出了有限置信模型,即个体在观点足够接近的前提下进行交流。HK模型就是一个经典的有限置信模型。
LPA 是一种具有简单算法逻辑的社区检测代表性方法。LPA 算法适用于代理之间存在某些联系的社交网络。代理的邻居是与代理有直接关系的人。例如,在合作科学家网络中,如果科学家有合著论文,那么他们之间就有联系。

唔姆,如图所示,以上是标签传播示意图。随着代理逐个更新,紧密连接的代理将获得相同的标签。
标签传播的概念很好地描述了社区检测过程。由于每个代理最初都有一个唯一的标签,先前的迭代使一些小的节点组获得相同的标签。这些具有相同标签的群体随后获得动力并试图吸收更多节点以加强其群体。
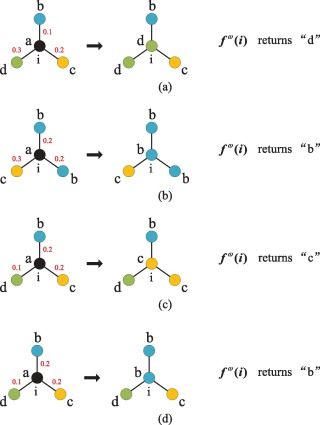
唔姆,如图所示,以上是LPA-HK 模型中标签更新的四个示例。代理i的邻居的标签权重以红色数字标记。代理i将选择标签权重总和最大的邻居的标签作为其新标签。如果有多个这样的标签,则随机选择其中一个。
简单一点说,模型的流程如下:
我们可以按照以下步骤描述LPA-HK模型。
- (1)初始化。分配一个唯一的标签和一个实数
最初作为网络中每个代理的意见。
- (2)迭代。集合t=1。
- (3)代理的随机排列。随机排列网络中的代理。
- (4)标签更新。对于按上述顺序选择的每个代理,选择标签权重总和最大的邻居的标签作为代理的新标签。
- (5)意见更新。每个代理的标签更新完成后,代理的意见将根据邻居的意见进行更新。
- (6)停止标准。如果每个代理都拥有其邻居的标签,且标签权重之和最大,并且所有代理的意见不再改变,则终止算法。否则,设置t=t+1然后继续。
我们通过模拟分析 LPA-HK 模型,重点关注模型参数对意见动态和社区检测的影响。为了更好地揭示模型特征,我们将模型应用于经常用于社区检测问题的真实社交网络案例。我们设置置信水平ε和邻居的可信度μ以0.01为步长从0变化到1。对于每个代理,我们在初始时刻分配一个唯一标签,并从区间中随机选择一个实数[0,1]作为初步意见。为了消除随机性的影响,我们在相同条件下进行了100次实验并取平均值。
置信水平和本文无关,所以重点关注邻居可信度。
为了检验邻居可信度对群体意见演化的影响,我们固定置信度的值,将LPA-HK模型应用于Zachary’s Karate Club网络。在同样的实验条件下,设置ε=0.4并将LPA-HK模型的观点演化与经典HK模型进行了比较。
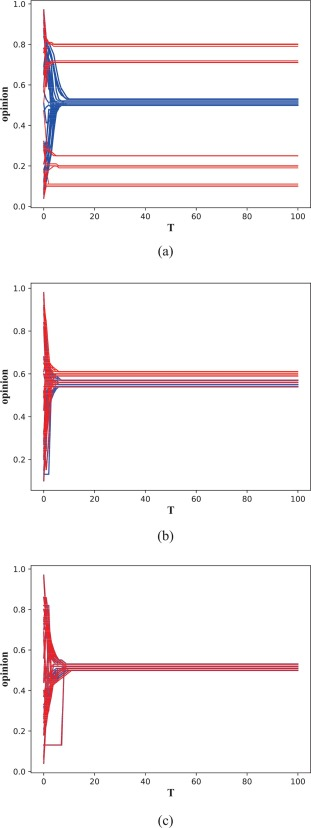
唔姆,如图所示,以上是网络群体意见的演变。(a)ε=0.4,μ=0.1;(b)ε=0.4,μ=0.5;(c)ε=0.4,μ=0.9。纵轴代表意见空间[0,1],横轴代表演化时间。细红线表示LPA-HK模型,粗蓝线表示经典HK模型。结论很明显,μ也会导致群体意见向共识演变。当μ较小时,代理人最终意见的分布在 LPA-HK 模型和经典 HK 模型之间表现出很大差异。与经典 HK 模型相比,LPA-HK 模型的意见更加多样化。然而,随着μ逐渐增加,最终两个模型的观点演变轨迹几乎重合。
为了进一步分析观点的演变,使用蒙特卡洛方法,绘制了代理最终观点分布的方差均值ε,在不同价值观μ下。对于每组参数,在相同条件下进行了100次实验,并记录结果。
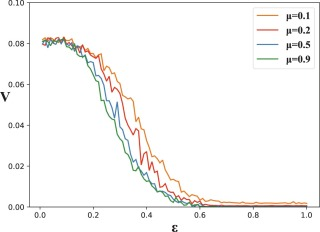
唔姆,如图所示,以上是实验结果。当群体的置信水平一定时,较小的μ会得到较大的意见分布方差,此时LPA-HK模型中的意见分布在意见空间中更加分散。另外,当μ较小,人口εc较大。这是因为当μ较小时,智能体对不同社区邻居的意见接受度较低,从而阻碍群体向共识演进。
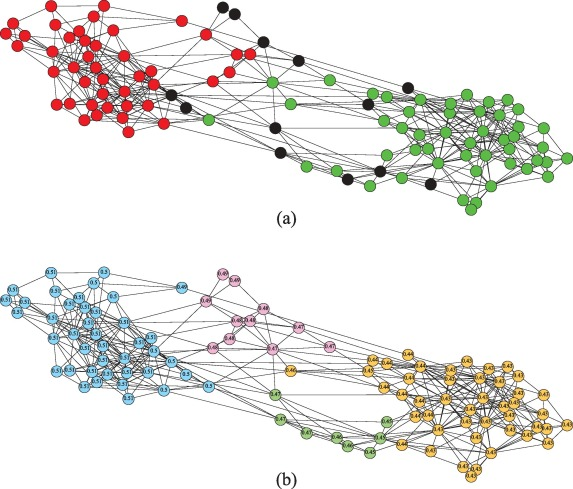
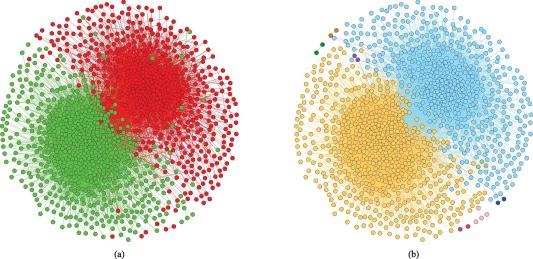
唔姆,如图所示,上图是书籍网络最常获得的分区图。(a)图表示原始的美国政治书籍网络分区;(b)图表示ε=0.9和μ=0.5数字表示进化结束时节点的意见,节点的颜色代表其所属的不同社区。下图是博客网络最常获得的分区图。(a)图表示原始博客网络分区;(b)图表示ε=0.9和μ=0.5. 节点的颜色代表其所属的不同社区。模拟结果表明,我们的模型可以揭示网络中节点的属性,当ε很大,网络中紧密相连的部分影响和吸收周围的智能体,形成一个社区,最终同一个社区内的智能体会达成相同的意见(我们在上一节中假设,如果两个智能体的意见值差异不超过0.2,则可以认为它们是一致的)。[2]
回到这个问题,我们可以初步猜测,各地的法院,会把同类例子之间进行合集,在后面碰到相似的例子时,比较倾向就会按照前面的例子去进行判断,最后的结果就是今天这幅“世界名画”。一句话概括,该类工作者之间的社区模块化较强,因此很容易得出相同的意见。
那么在这种规则下,不建议男性在对自己不利的规则下进行博弈,最起码的是,要让自己进入社区间的中间地区,这样才能保证形成支持自己的声音。