人工智能中大模型和小模型的实际应用区别是什么?
发布时间:
2024-10-08 05:51
阅读量:
41
大家好,我是TFlow AI的产品负责人。负责一款B端Agent的产品策划。TFlow AI 产品简介:是面向B端Agent平台,主要做模型应用层的开发。包含:任务流程agent、助手agent,rag等标准化的SDK,企业可以直接使用SDK等完成二次开发,从而为业务提效。
目前主要的SDK“任务流程agent”:能按流程处理任务(SOP),围绕目标来进行离散推理。能快速搭建Ai客服、AI导购等应用。体验地址:点击体验
今天我们来看下,传统AI1.0和大模型AI2.0他在应用开发上有什么区别
传统的AI 1.0的开发使用过程
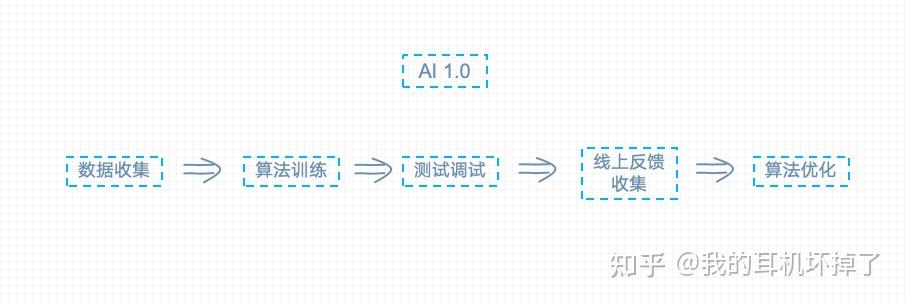
首先需要内部数据,这些数据可能来自多种来源,比如文件、数据库等等各种用户数据,文档内容。基于这些数据,构建数据分析平台或数据中台。处理了大量的数据,用各种小模型,最终将训练结果用于应用层。
例如,如果想要建立一套推荐系统,目标是将产品推荐给合适的用户,他的整个过程如下
- 1、数据获取:获取大量与用户行为数据和购买记录数据。
- 2、训练算法:使用一些推荐算法,如基于内容的推荐算法、基于协同过滤的推荐算法。
- 3、测试计算:使用测试数据集,模拟当用户访问某个平台或网站时,基于用户已有的行为数据,进行计算匹配。计算出我最合适的产品。查看模型在测试集上的表现
- 4、反馈收集:当测试集数据集合格,需要将应用面向终端用户。推荐的结果,用户可能会点击推荐的商品,也可能忽视推荐。需要将反馈结果收集,并传递到数据端。
- 5、算法调整:基于结果,进行二次反馈调整
大型模型的AI 2.0开发使用过程
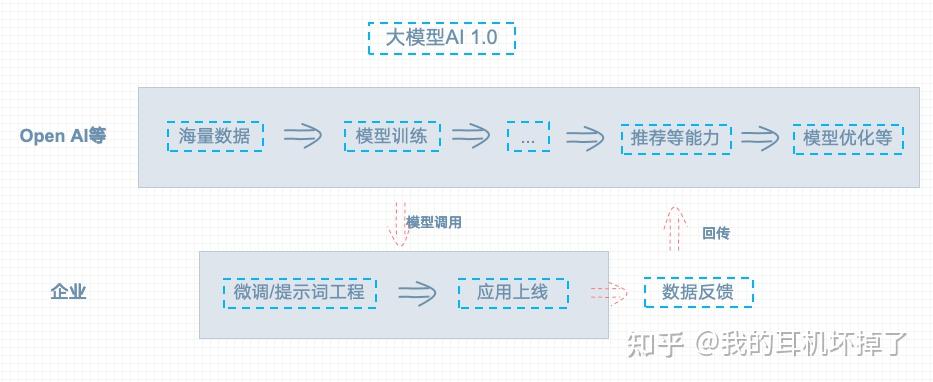
它的逻辑与传统1.0AI完全不同。
模型的开发
- 1、依赖于海量数据,可以被视为全球人类已知的数据知识。
- 2、基于这些数据,训练出通用的大模型。模型具备很多能力,如推荐等等。
- 3、当给一个用户的数据,模型就会自动推荐商品。于企业的业务特性,需要做个性化处理。
企业的应用
- 1、企业只需将通用大模型稍作调整,以适应我们自己的场景。通常通过prompting和微调,将通用大模型适配为企业需要的模型。
- 2、在应用层,同样可以通过收集大量反馈数据,将数据反馈到模型中。
模型的优化
- 优化的流程,在外部进行,与企业关系不大。
- 由通用大模型公司负责升级,如百度、Kimi等。
- 作为企业只需要做好适配,当然在prompt和微调也需要一些企业内部数据,但和海量数据相比,这里的数据量相对较少。
传统AI和大模型的AI什么区别昵?
- 1、通用大模型其能力足够强,我们甚至不需要进行额外的工作,可以直接应用大模型。
- 2、在应用场景中,企业开发工作将逐渐变得轻松。我们所做的更多是对通用大模型的适配,而不需要像AI 1.0时代那样从零开始训练模型。通用大模型能力越高。需要做的开发工作将变得越来越轻松。
- 3、如果将来通用大模型真的非常聪明时,甚至不需要进行大模型的微调。
总的来说,随着大模型能力的增强,构建一套AI应用场景的门槛正在降低。
技术平权的时代来临!
END