 "模型"搜索结果 46 条
"模型"搜索结果 46 条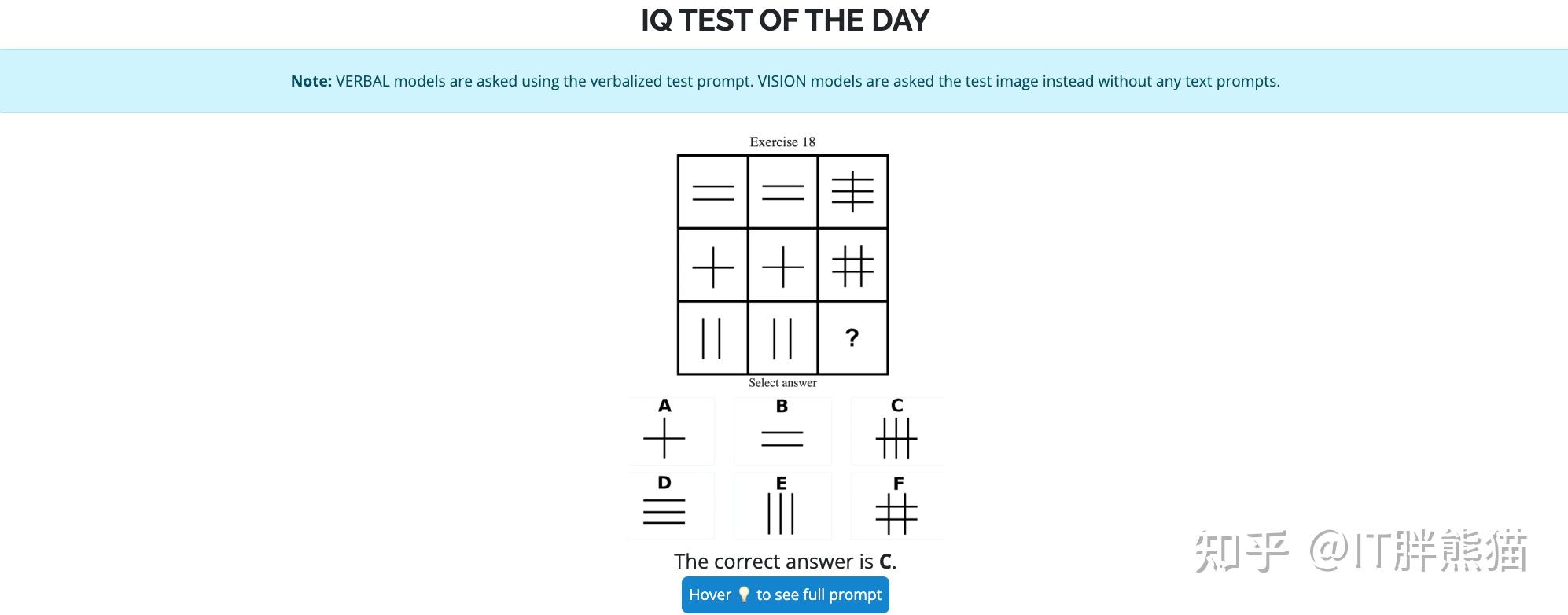
如何评价谷歌最新发布的Gemini 2.5 pro模型?
似乎没人说啥呀,那就只能一个评价了:差强人意,勉勉强强吧。不是它不行,是市场已经麻木了,实现不了对前三的超越,就只能是这个情况。 GPQA(Graduate-Level Google-Proof Q&A Benchmark)是一个用于评估高级问答系统的基准数据集。该项目旨在提供一个具有挑战性的问答数据集,以测试和提升AI模型的问答能力。GPQA数据集包含复杂的问题和答案,适合研究生级别的学术研究和工业应用。不过也有对它表扬的,它确实做智力测验比较…
如何看待匿名网友爆料,宣称 Meta 开源模型 LLaMA 4 作弊,将测试数据混入后训练数据中?
经过反复训练后,Llama 4未能取得SOTA,甚至与顶尖大模型实力悬殊。 为了蒙混过关,高层甚至建议: 在后训练阶段中,将多个benchmark测试集混入训练数据。 在后训练阶段中,将多个benchmark测试集混入训练数据。 最终目的,让模型短期提升指标,拿出来可以看起来不错的结果。这位内部员工@dliudliu表示,「自己根本无法接受这种做法,甚至辞职信中明确要求——不要在Llama 4技术报告中挂名」。 另一方面,小扎给全员下了「死令」…
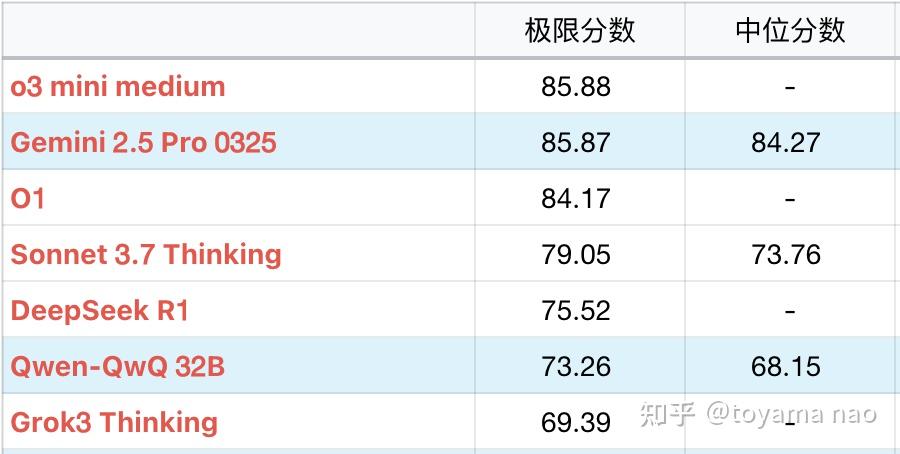
谷歌发布 Gemini 2.5 Pro 模型,称其是一个「思考」模型专为复杂任务打造,它有多强大?
Gemini 2.5 Pro Experimental 03-25一句话总结: Google也要给OpenAI上强度了24号DeepSeekV3教育OpenAI什么是好用又便宜的基础模型,25号Google也来给OpenAI上强度,什么是免费又好用的推理模型。 2.5Pro作为一个推理模型,速度还是挺快,测试的平均耗时控制在50秒。这速度虽然比不上自家flash thinking,但在一众推理模型里算快的。 在这个速度上,2.5Pro的成绩达到了85分的极限分,并且其稳定性相当好,中位分仅低1分(2%)。绝…
OpenAI 称 DeepSeek 是另一个华为,呼吁对中国 AI 模型实施禁令,为什么它会这样做?
OpenAI 已经无路可走了。 后面追赶的 DeepSeek 使用了大量 OpenAI 视为核心机密的技术,比如 RL、稀疏 MoE,还创新了 GRPO、MLA、FP8 混合精度训练等技术,在工程化和成本上远超 o1 模型。 前面领跑的 Grok 3 又把路堵死了,20 万张卡也不过如此,烧钱是一方面,数据也是个难题,纽约时报等传媒还在围追堵截 OpenAI。 中间的竞争者 Anthropic 又断绝了应用的后路,Sonnet 3.7 在大模型最主要的编程能力上一骑绝尘,OpenAI 连灰都…
2025年大模型LLM还有哪些可研究的方向?
抛砖引玉一下。我觉得现在其实很多原理上的问题甚至都还没解决,例如,llm数strawberry的r,乍看起来好像很自然,但tokenizer切分subword可从没向llm暴露subword的组成,那么llm是从哪些数据或者哪些模式学到这个token包含多少个某字母呢?类似的,现在的llm可以写押韵的歌词,tokenizer可从没暴露这个token的发音,这又是llm从哪些数据学到的呢?如果真的用sae等工具分析,似乎总能得到一些惊世骇俗的结论,例如和圣经的激活模…
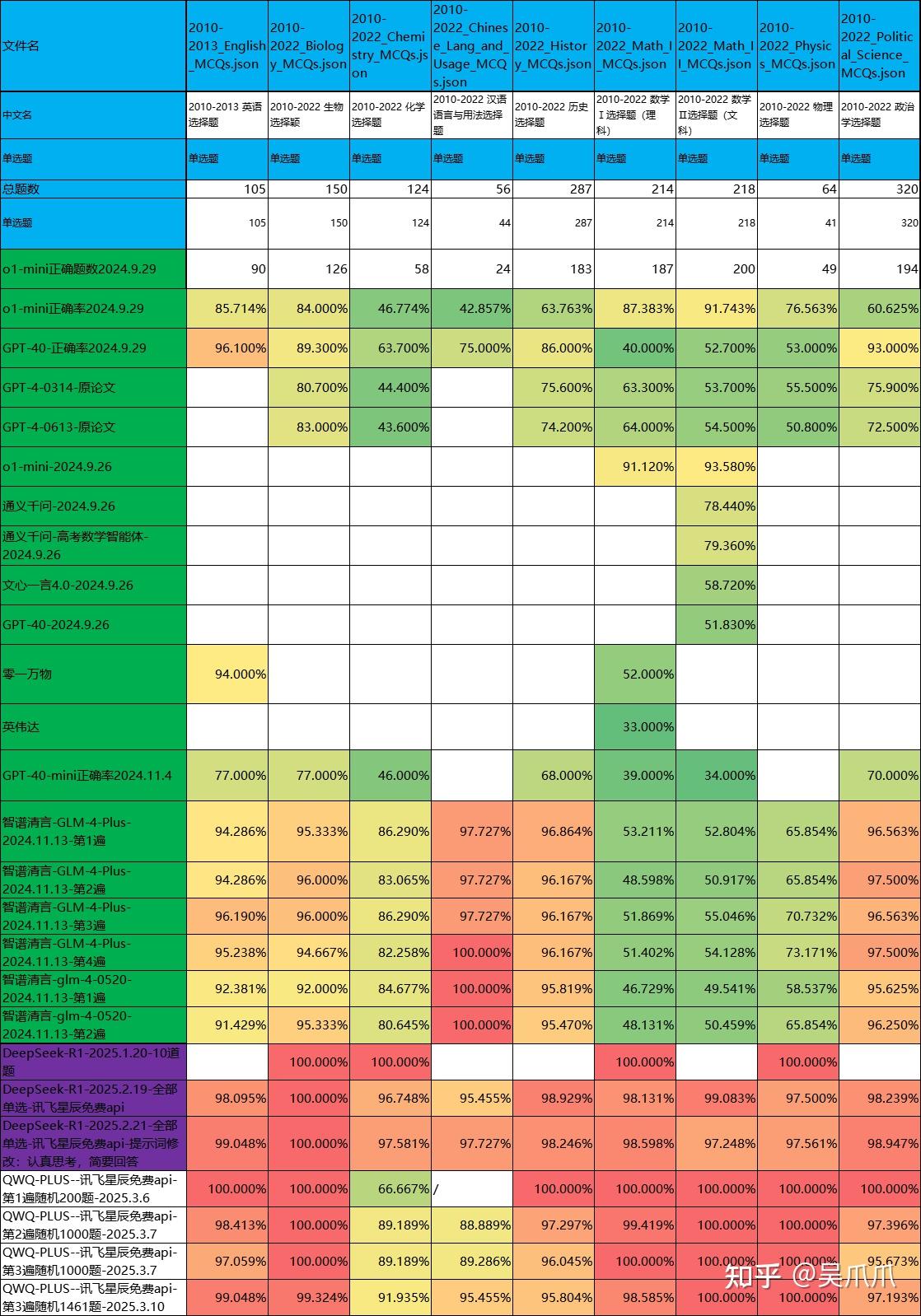
阿里巴巴发布开源推理模型通义千问 QwQ-32B,它的水平如何?
步骤: 0、上周做了QWQ32b、Deepseek-R1历年高考真题1500题测评,数学正确率在满分、99%范围,一个大伙比较关心的疑问是AI是不是背历年真题。 0.1、采用AI自己出新题、AI答题的方法尝试测试AI有没有背题。 1、正式开始。 2、提示词,出新题 3、代码 4、得到QWQ32b、Deepseek-R1各400、800道题 5、AI重新答题。 QWQ正确率平均96%,做QWQ自己出的题目99%,做Deepseek出的题目正确率95% Deepseek正确率平均96%,做QWQ出的题目96%,…
大模型算法是否会催生一大批不懂业务的算法工程师,热度过后他们将何去何从?
不用等热度过后,要不了多久就会开始有应用算法工程师失业了 你看现在llm应用算法工程师和bert时代干的活有啥本质区别吗 接需求->洗数据->选模型->训练调参->解bad cases->上线->收bad cases->解bad cases...如此循环 两年后这些事儿产品+agent+工程就包了大部分了,还要那么多应用算法在那半年磨不出一个能用的模型干嘛
如何看阿里最新开源的推理大模型QwQ-32B效果接近DeepSeek R1满血版?
感觉差距还是不小的。 我问deepseek R1和QwQ-32B这样一个问题:小红有两个姐姐,两个妹妹,请问小红的妹妹有几个姐姐?这个问题存在唯一答案吗? deepseek R1答3个且唯一,告诉它结果不对,马上能够纠正错误,并且找到推理错误的地方。 QwQ32B也是同样的答案,但是如果只是回复答案不对,它还是会一直坚持它最初给的答案,需要指出逻辑错误的地方才能纠正过来。在指正的时候,还需要讲得非常清楚,它才会意识到错误。

阿里发布开源推理模型 QwQ-32B,支持消费级显卡本地部署,有哪些技术亮点?
昨天晚上在推就看到训练完毕了,然后在魔搭群里帮着测试了一下,感觉效果很不错! 下面是我常用的五个问题: 1.我是谁测试模型人称和自我指代的能力,之前很多非推理模型都过不了

解析或者讨论下何恺明带学生新作,扩散模型不需要噪声时间条件?
呃呃,我真的无语了。你要说的话VAE不就是blind denoising嘛。。。甚至现在VAR的scaling里面也会加一点噪音在里面增强鲁棒性。 其实不要条件本来就可以做,比如我之前看过一篇的扩散模型的可解释理论: Generalization in diffusion models arises from geometry-adaptive harmonic representations 就是引用的Robust and interpretable blind image denoising via bias-free convolutional neural networks,用的bias free netwo…

石门中学本土化部署 DeepSeek 671B 完整版,大模型将如何改变教学?
从各平台媒体上收集新闻,基本形成了一个轮廓,就是一个本科毕业三年的人在2月13日花十万注册这家公司后与石门中学达成合作,用八张N卡跑671b模型(根本跑不动无量化的别想了),甚至N卡有没有A100都难说。至于所谓的教育平台,实际上就是chatbox这一开源软件。至此,还希望羊城,南方+等南粤主流媒体能进一步关注石门中学在智慧教育中的下一步! 分割线 671b无量化,16张华为910B或者A100起步,大约240万元,但这个并发数大概六…
本地部署DeepseekR1671B模型需要什么配置?
今天下午用ktransformers在4090上跑了下R1的4bit量化版本,模型大小370多G,按照框架要求需要380多G的CPU内存,直接在autodl上开的4张卡,实际推理只用了一张卡,过程很顺利,就是速度着实慢,官方decode是12token/s,我跑的实际上8token/s,可能CPU比较差吧。 这个框架底层用的是llama.cpp,外接的python接口,之所以这么快是因为英特尔CPU指令集更好的调用内存,再就是只讲激活的专家放到GPU上。 个人使用也能接受,就是380G内…
为何国内其他推理模型没有像deepseek一样爆火?请先看说明。?
当今学术研究和论文写作的过程中,文献检索是基础性工作之一,重要性不可忽视。 文献的广泛性与深度直接决定了研究的质量与深度。传统的文献检索方法,如图书馆的纸质资源查询,或通过网络搜索引擎查找相关文章,在一定程度上有效,但在面对日益庞大的信息量时,往往显得力不从心。随着人工智能技术的不断进步,许多学术搜索引擎应运而生,为研究人员提供了更高效、更精准的检索工具。DeepSeek 正是其中的佼佼者,它以智能化的检…
如何看待 DeepSeek 深夜发布的全新多模态大模型 Janus-Pro-7B?带来了哪些影响?
虚假的金融核弹:禁止使用SWIFT结算系统。真正的金融核弹:DeepSeek。犹记得前两年黄仁勋嚣张异常神神们小人得志的模样,扬言中国根本制裁不了英伟达,现在回旋镖来了,不但制裁你英伟达,连你整个美股我都要制裁,一天跌掉上万亿美元的市值。索罗斯做梦都想狙击中国股市,可惜屡战屡败,铩羽而归。而幻方量化一家公司却精准反向狙击了美国股市,真所谓打败你的不是同行而是跨界。更搞笑的是,苹果因为太菜在AI领域迟迟没有大动…
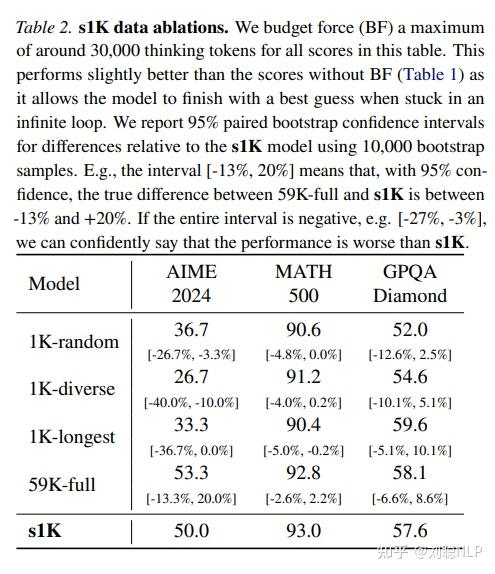
如何看待李飞飞团队用不到 50 美元训练出媲美 DeepSeek R1 的 AI 推理模型?
这里要给大家先说几点,避免其他文章被带入到误区。 s1超过的是o1-preview,没有超过o1甚至o1-mini,有很大区别s1的效果不敌deepseek-r1 800k数据蒸馏的32B模型,差了不少,不是媲美s1即使使用全量59k数据的效果也没有提高很多,甚至在math上还有下降,所以核心是数据质量1k数据是从59K数据中筛选出来的,不是直接有1K数据就可以s1使用1k数据是节省了训练时间,但蒸馏的难点在蒸馏数据的构造上好了,下面开始介绍s1。 s1的本质是…
Altman 承认 OpenAI 的闭源策略站在了历史的错误一边,将逐步开源些旧模型,这是怎样的信号?
孙正义听到这话,怕是连想杀人的心都有了,这不是刚上船就被Altman给卖了吗。 我们抛开技术上的问题不谈,单纯从商业逻辑上来看这个事,Altman的这句话无疑是把所有投资者都给卖了,因为闭源能给的是一个AI帝国,而开源能给的只是一个网络服务商,闭源对于投资者来说实在是太重要了。 从投资者的角度来说,不管闭源到底有没有错,Altman就不应该说这样的话,即使是不说会让OpenAI倒闭也不能说,就算是真错了也只能一直错到底,这…
deepseek v3模型为啥要开源?
这些年科技圈总在玩"开源"行为艺术,SpaceX开源,可有几个国家能造火箭?波士顿动力开源,又有几个国家造出机械狗?直到DeepSeek把世界顶级AI模型免费开放,大家才明白什么叫科技平权。真正的革命从不是精英游戏,这操作相当于给全球70亿人发了把金钥匙,以前需要百万年薪专家才能调教的AI,现在初中生都能用手机调用,这才是真正的人类文明之光,它将成为照亮每个平凡人命运的万家灯火,我愿称之为科技共产主义运动。
微软一边开展调查一边又要接入使用,宣布优化DeepSeek-R1模型,这么做目的是什么?
微软善于投机,当它从中国赚取更多钱时,是一种嘴脸,当它从中国赚的钱少时,就开始污蔑中国。尤其是为了获得美国的国防合同,加大了对中国抹黑的力度。 抹黑DeepSeek是为了OpenAI,主要是DeepSeek的出现,让OpenAI极度贬值,帮助OpenAI就是希望OpenAI能够重新恢复估值,能够继续赚钱,毕竟微软已经投入了上百亿美元。 而继续使用DeepSeek,就是为了用DeepSeek去吸引用户,挽留微软的用户。此外,还可以立个贞节牌坊。宣传自己没…
印度紧随 DeepSeek 要搞自己的 AI 模型,称将与世界上最优秀的模型媲美,印度研发能力怎么样?
看每个答主恩都在调侃阿三,但这次有点邪门,可能deepseek真的把阿三给刺激住,这两天我在外网看到大量阿三在反思,不是几个头部博主反思,是连评论区里也充斥大量的反思言论,我特么看外网这么久,第一次发现阿三不自信了,甚至很多反思又滋生出中吹出来,有些吹的过了,把我看的都不好意思了
如何评价DeepSeek等大模型在中科院物理所理论竞赛中的表现?
DeepSeek(DS)我已经用了一段时间了,对于DS在中科院理论所理论竞赛中的优异表现并不诧异,实际上,DS还可以执行更难的任务。更何况这里面绝大多数的竞赛试题并没有太多的新东西。 我之前将一篇论文输入到DS当中,让其经过一顿分析,了解这篇文章的大致结构体系和计算结果,然后让其根据类似的方法计算别的体系,然后就得到了另外一篇文章的结果,这种模仿炒菜式的科研方式,在未来可能很快会被DS代替。甚至DS还可以根据一些具体…