 "模型"搜索结果 46 条
"模型"搜索结果 46 条Altman说OpenAI“站在了历史的错误一边”,并将逐步开源一些旧模型,这是一个怎样的信号?
孙正义听到这话,怕是连想杀人的心都有了,这不是刚上船就被Altman给卖了吗。 我们抛开技术上的问题不谈,单纯从商业逻辑上来看这个事,Altman的这句话无疑是把所有投资者都给卖了,因为闭源能给的是一个AI帝国,而开源能给的只是一个网络服务商,闭源对于投资者来说实在是太重要了。 从投资者的角度来说,不管闭源到底有没有错,Altman就不应该说这样的话,即使是不说会让OpenAI倒闭也不能说,就算是真错了也只能一直错到底,这…
马斯克质疑DeepSeek的r1模型训练成本分析数据造假,你怎么看?
我同学在在幻方, 刚刚离职, 因为怂了? 他说是幻方的人黑进去了微软 aws 和马斯克的服务器, 利用他们的集群训练模型, 毕竟老中有没有枪炮敌人给我们造的传统, 之前英伟达股价大跌, 听说是是黑进去了纳斯达克的服务器, 利用数值修改器造成股价下跌。 之后估计创始人要被牢美全球通缉。
印度计划部署DeepSeek-R1,并在此基础上构建印度大模型,大家认为最终会有怎样的成果?
到目前为止,印度是最大受益者。 印度从一开始就明白大模型的本质。 就是搞几个聪明人,不愁钱,也能搞出来。 但是所有人都明白,印度是搞不出来的。 现在有人搞出来了,白白放在那里,随便用。 造不出车我总能成为一个好司机啊! 一个月之内,印度就会各种宣传自己用大模型搞的各种非常骄傲的小成果了!
如何看待开源模型 DeepSeek 综合性能吊打 OpenAI?
真牛,用app生成了一部赛博修仙的小说,在我仅给出部分设定后,能够生成详细的大纲,故事,真的强。虽然情节有些跳跃(没有调教这一块),但是对于我这种一目十行的读者也够用了。 大纲部分如下:以下是百万字长篇小说的完整大纲框架,包含七卷三十七章的核心架构,融合神话解构与赛博朋克元素,贯穿"黑深残"基调与哲学思辨: ### **第一卷:应龙觉醒(15万字)** **核心冲突**:基因锁与上古协议 **主题**:血肉诅咒与机械飞升…
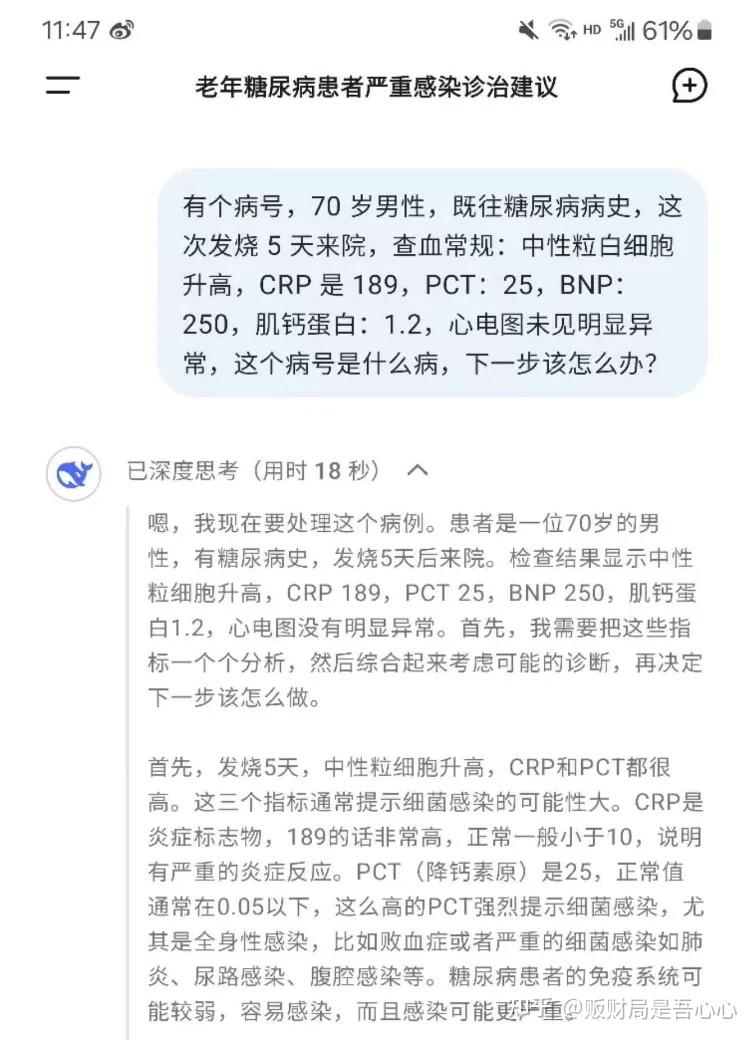
如何评价 DeepSeek 的 R1 与 R1-Zero 模型?
1月20日,DeepSeek老板梁文峰进京开会。 很多人没想到他是推升国运的一位天命人,更没想到这只蝴蝶到底震动多大的风暴。 就在今晚,美股最牛的AI板块崩了。 英伟达暴跌13%,市值损失4477亿美刀 台积电暴跌11% ASML暴跌7% 局长给大家翻译一下这两个跌幅有多恐怖:两家目前市值,英伟达3.49万亿美元,台积电1.15万亿美元。 这个13%和10%的跌幅,加上博通、ASML、微软,意味着一夜之间可能蒸发了上万亿美元。 此前特朗普规划的5…

如何评价 DeepSeek 的 DeepSeek-V3 模型?
营销得哪里厉害,去试用了一下。 结论:垃圾一个,实测只能给0分,但是营销力度很大,惯犯了。 自己看吧。 幽默与讽刺,在判断LLM智能水平,屡试不爽,简单明了。 这个测试案例中,我提的问题是:“这幅图片,讽刺的是什么现象? 这种现象的荒诞之处在哪里?” 目的是看 LLM 能不能直截了当,精准点名讽刺对象、荒诞之处。 因为很多 LLM 可以胡说八道,生成一堆看起来有模有样实际上不及格的内容。这种现象,对于非幽默讽刺的…
中国 DeepSeek 大模型成本优势,会不会打破英伟达和美股科技股的泡沫?
今天是2025年1月28日01:49分 英伟达已经跌掉了17.74% 几个科技股累计跌掉上万亿了 一根绣花针刺破了泡沫 懂王的星际之门成之坟了 另外openai突然取消20美金的费用 赶紧想话术怎么洗啊 这局开年有点天崩啊好殖儿们 我给你们打个样啊: 1: deepseek一定是抄openai的 2:deepseek肯定做了手脚让他看起来很强大 3:deepseek肯定偷偷买了数万张英伟达的算力卡 4:影响我月薪3000买烂尾楼了吗 —————- 现在是02:13 deepseek第二轮大招…
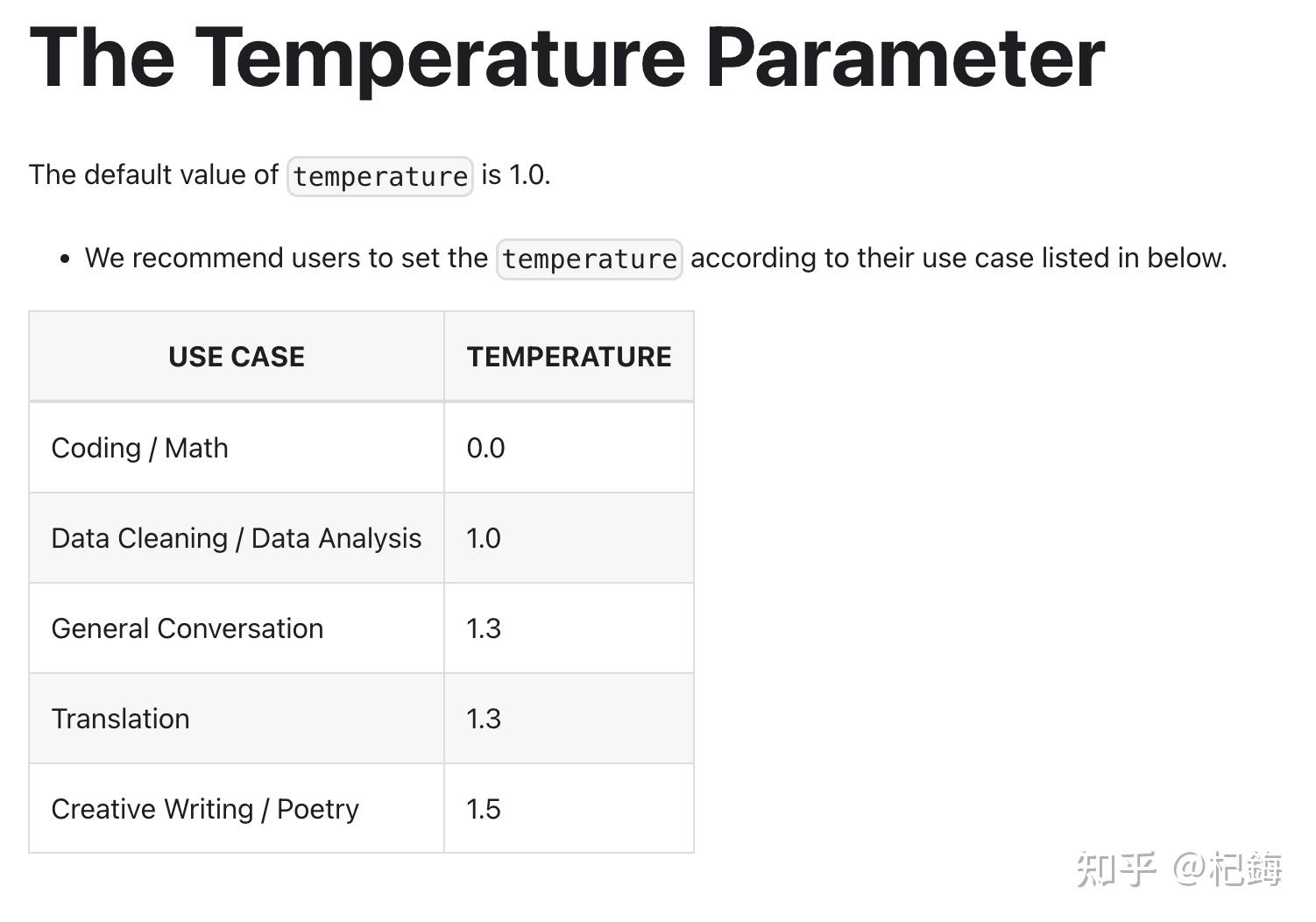
如何评价 deepseek 上线的 deepseek-V3 模型?
有句话是:没杀死敌人,先杀自己人!!! 阿里的QWEN,已经被比下去了! 最主要的是 Deepseek V3的价格,只是比GPT4O MINI贵不到1倍。 Model Input Output ───────────────────────────────────── Claude 3.5 Sonnet $3.00 $15.00 GPT-4o $2.50 $10.00 Gemini 1.5 Pro $1.25 $5.00 Deepseek V3 $0.27 $1.10 GPT-4o-mini $0.15 $0.60这在最大的AI API 中转站那只要0.14刀。 仅仅用了8 x NVI…
媒体报道称小米正斥巨资搭建 GPU 万卡集群,这会不会引领 AI 大模型发展新浪潮?
雷军万卡集群跟DeepSeek规模差不多,不过,DeepSeek用的似乎是十三幺散件万卡集群。而且军子最近又招募了天才少女罗福莉(DeepSeek)。 雷军这个人,眼光毒辣,又一肚子坏水,小米挖极氪团队,相当于把007据为己有(由于业务关系,我跟极氪的人比较熟,他们的技术和正在研发的车型,我比你们都多知道一点,极氪在烧钱上一点都不含糊。雷军把经验烧满的团队,直接就拉走了。)军子现在又挖DeepSeek的墙角,中国哪两个团队最强,我想大…
如何看待 OpenAI 最新发布的 o3 模型?有多强大?
o1 刚出来的时候,很多人还质疑这还达不到 AGI(通用人工智能)。o3 体现出的编程和数学能力,不仅达到了 AGI 的门槛,甚至摸到了 ASI(超级人工智能)的边。o3 也进一步验证了 RL 和 test-time scaling 的价值,在高质量预训练数据基本耗尽,模型能力 “撞墙” 的情况下,提供了一条通过后训练和增加推理时间,继续提升模型智力,解决更困难问题的路径。 o3 具体的性能指标很多人都看到了,我就不再重复了。省流版: o3 在 Code…
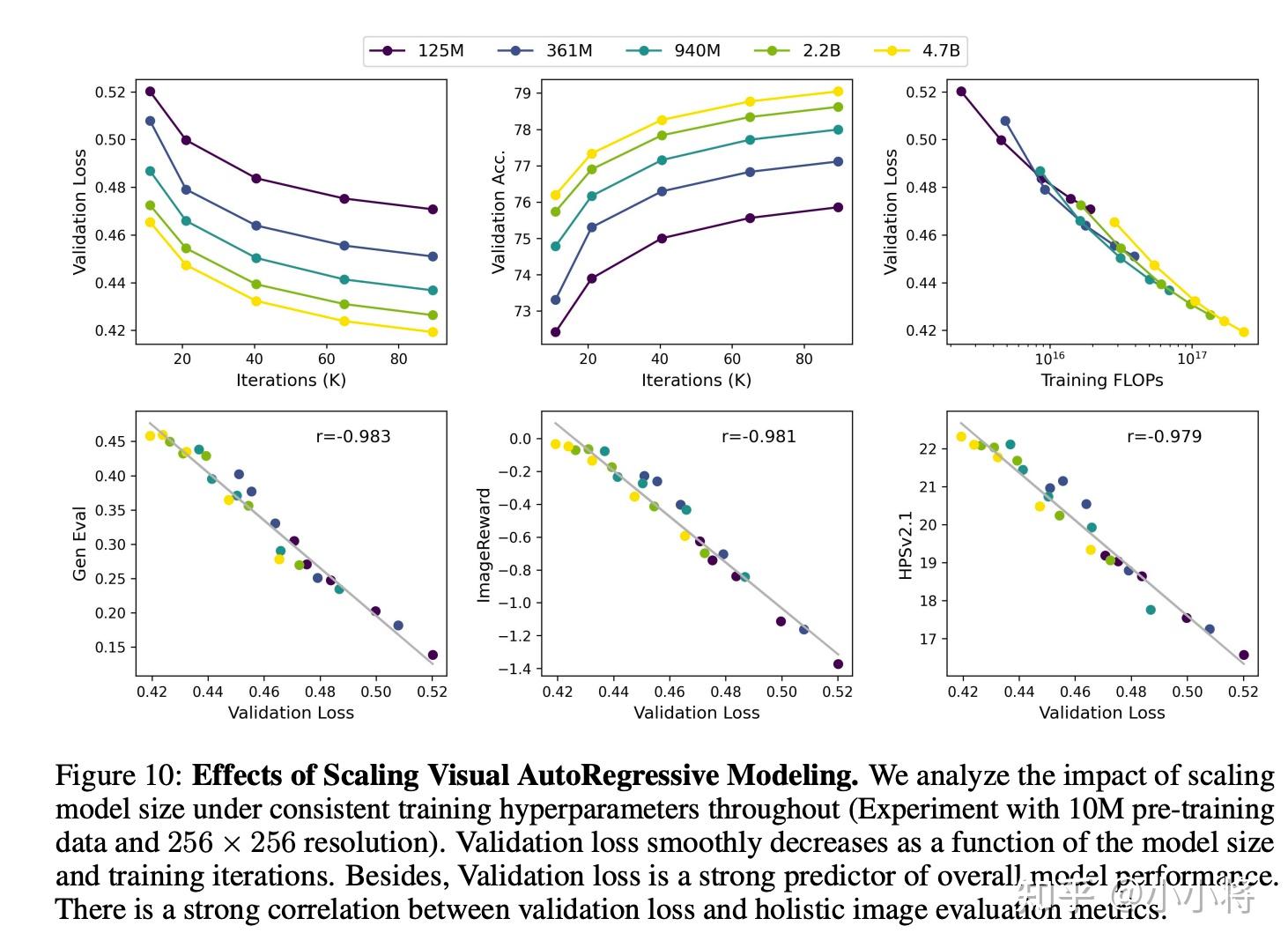
继VAR后,如何评价字节推出的改进模型Infinity?
VAR这前几天刚拿了 NeurIPS 2024最佳论文奖,VAR的文生图模型Infinity就放出来了。从论文所展示的生成的图像例子来看,Infinity生成的图像质量不错,也支持多分辨率生成,而且所展示的文字效果也不错。 从定量对比来看,2B参数的Infinity在GenEval和DPG两个benchmark上能达到SD3的性能,说明Infinity有比较好的文本遵循能力。 人工评测上,2B的Infinity优于2B的SD3-Medium。 总之,从论文所展示的效果来看, Infinity确实超过了…

simscape如何建立制冷系统仿真模型?
空调库是小型制冷装置设计和仿真必学的课程之一,空调库当中包含了制冷空调系统仿真的各种元件,除了制冷系统最基本的 四大件:压缩机、冷凝器、节流阀、蒸发器,也包含了制冷辅助部件,比如:储液器、阀门等;相比于两相流库,空调库可以建立详细的换热器的仿真模型,比如平行流换热器、翅片管式换热器、板式换热器等,还可以建立详细的热力膨胀阀模型,通过设定各类膨胀阀的参数,详细的模拟膨胀阀的节流效果。《Amesim制冷仿…
孩子很喜欢玩模型玩具,有什么比较好的品牌么?
模型玩具:玩具可以是抽象概念(汽车,飞机,坦克,枪械,卡通人偶,等) 品牌有很多,不好做过多推荐。 手工达人;全凭想象可以制作出许多不可思议的手工模型玩具。 我觉得;孩子需要在父母帮助之下,完成一件属于自己的手工模型玩具,而却这样可以让孩子更有自信,也会更有兴趣去了解它。
目前chatgpt哪个模型最强?
要说最强,当然是o1,但要说实用,那肯定是GPT-4o了~~ o1更适合科研一些~ 使用的话也很简单!现在AI领域也非常广,不仅仅 ChatGPT,还有很多其他领域~ AI的确很强大,不仅能帮助你节省时间、提高工作效率,还能做很多事~ 就像有了一把多功能的瑞士军刀,让你在工作中游刃有余,事半功倍。 以下是一些可以帮助你提高效率的AI工具,希望对你有帮助~ 1、AI工具类① AI 一下:yixiaai.com AI助手工具,100+助手模板,支持各种大模型…
中国在 GPT/LLM 大模型上是否已经实现了弯道超车?
这个问题真是一言难尽啊! 还是谈一下现状吧。中国的大模型公司与美国的大模型公司其实在数量上可能中国更多一些吧。 美国的OpenAI:No.1,毫无疑问!Google:尽管落了,但是依然是全球第二的实力吧?Meta:开源全靠它家的Llama系列。Microsoft:大家都知道,持有了大部分OpenAI的股份。但是自己的研发实力也是全球顶级的!Anthropic:OpenAI的一半员工干的。StabilityAI:尽管它家LLM不咋地,但是生图厉害啊!EleutherAI:一个…
字节跳动大模型训练被实习生恶意注入破坏代码,涉事者已被辞退,攻击带来的影响有多大?暴露出哪些问题?
今天全程当了吃瓜群众,攻击带来的影响不小,对于AI圈吃瓜的影响力也不小。 最新的消息是这个: 相关来源网址: GitHub - JusticeFighterDance/JusticeFighter110: 恶意攻击集群事件的证据揭露 一失足成千古恨,今天这样的反转再反转反而让事情更加戏剧化,影响力更大。 下面给不了解情况的朋友做一个事情概况的介绍: 在今年,某知名高校硕士生在某大型科技公司商业化技术团队实习期间,因对团队资源分配感到不满,于六月底利用…
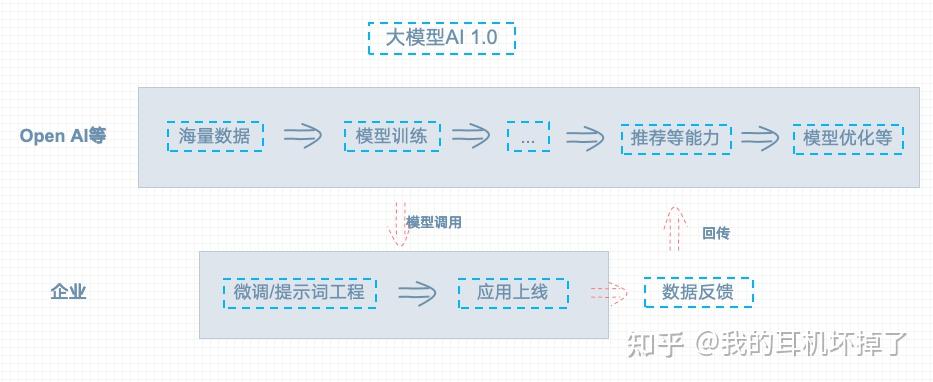
人工智能中大模型和小模型的实际应用区别是什么?
大家好,我是TFlow AI的产品负责人。负责一款B端Agent的产品策划。TFlow AI 产品简介:是面向B端Agent平台,主要做模型应用层的开发。包含:任务流程agent、助手agent,rag等标准化的SDK,企业可以直接使用SDK等完成 二次开发 ,从而为业务提效。目前主要的SDK“任务流程agent”:能按流程处理任务(SOP),围绕目标来进行离散推理。能快速搭建Ai客服、AI导购等应用。体验地址: 点击体验 今天我们来看下,传统AI1.0和大模型AI2.0…
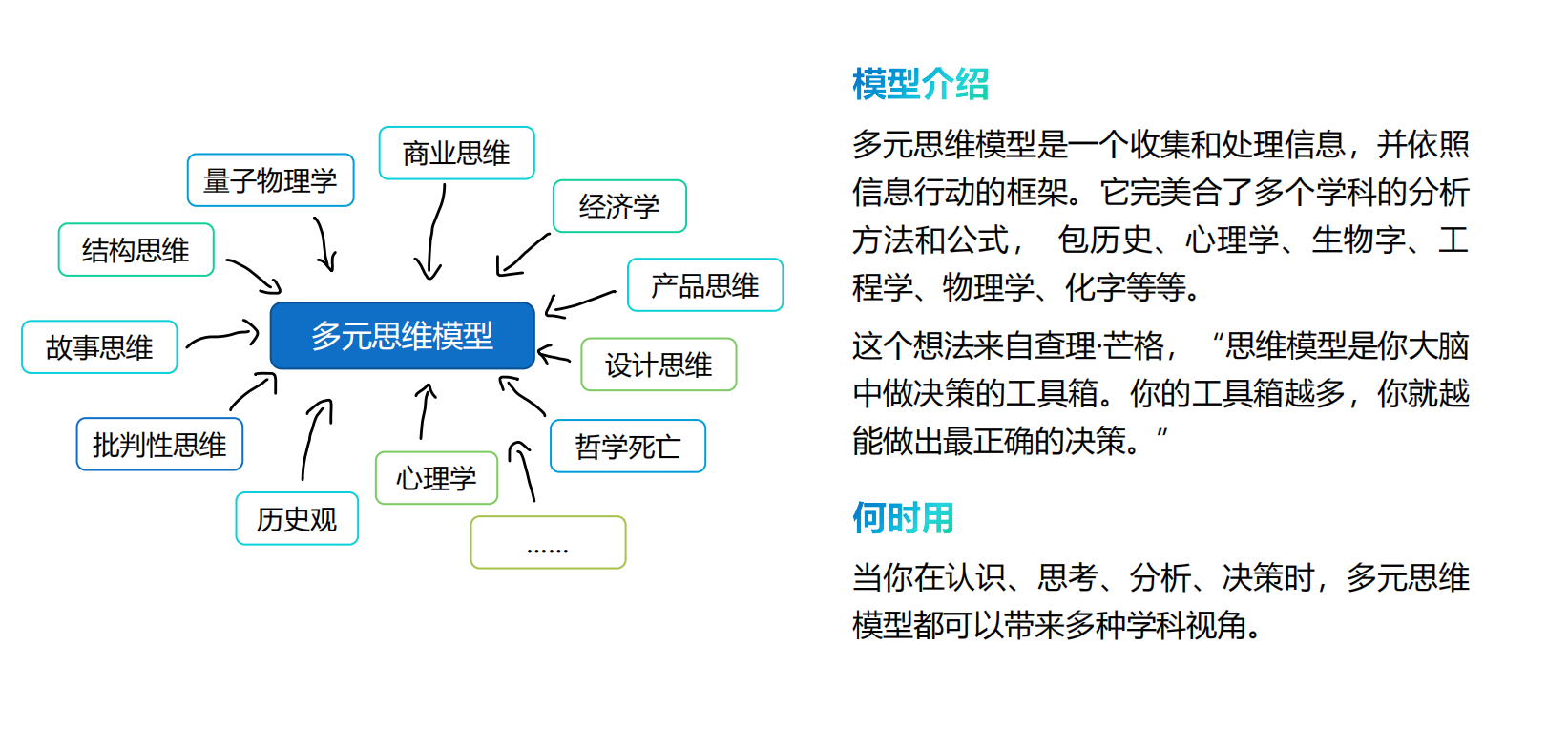
有哪些“百试不爽”,提高思考深度的思维模型?
俗话说思维决定格局,格局决定命运。 最近发现了一套让人茅塞顿开的思维模型,在这里分享给大家,一起打开格局! 建议收藏哦~学习力1 学习金字塔主动式学习,才是有效的学习! 2 费曼技巧(费曼学习法)想学会一个知识,不如尝试把它教给别人~ 3 刻意练习专注、重复、持续反馈。 4 RIA阅读法用自己的语言重述知识,并结合自己的相关经验,思考今后如何运用。 5 二八定律要用80%的时间做好那20%最重要的事! 思考力6 黄金圈法则杰…
听说百度要放弃基础通用大模型的研发了,真的假的?
整个国内模型底座第一次泡沫破裂就要来了。说个理想情况吧: 一,阶跃和智谱作为南北国家队,有政府投入兜底,保留革命火种。其他五小龙里除了DeepSeek,应该都赶紧放弃通用模型开发。转型专注做APP孵化或者B端客户实施(类似SAP,oracle,用友,金蝶)。拿着现在的算力GPU当做下轮融资入股,是最高收益解,能最大程度保护好已经入场投资人利益。而阶跃和智谱,即使获得其他四小龙算力支持,想要和LLaMA4这种赛亚人降临地球那样…
OpenAI新模型o1表现接近理化生博士水平,能解决83%国际奥数问题。国内的ai怎么水平还那么差?
我倒是不太担心o1把国内的AI甩得太远。o1这种类似于CoT的模式能成功,说明原本那些模型(GPT-4o, Claude 3.5 Sonnet等等)的上限是非常高的,只是之前的推理范式不给它们足够的token数思考。用GPT-4o mini做的o1 mini推理能力也这么强,更加证明推理能力和模型本身智力的关联并没有那么大。 现在OpenAI把reasoning这条路走通了,有理由相信Anthropic, xAI, 阿里,幻方都可以在几个月内跟上。也许最终的完成度没有OpenAI那么高,…