继VAR后,如何评价字节推出的改进模型Infinity?
VAR这前几天刚拿了NeurIPS 2024最佳论文奖,VAR的文生图模型Infinity就放出来了。
从论文所展示的生成的图像例子来看,Infinity生成的图像质量不错,也支持多分辨率生成,而且所展示的文字效果也不错。



从定量对比来看,2B参数的Infinity在GenEval和DPG两个benchmark上能达到SD3的性能,说明Infinity有比较好的文本遵循能力。
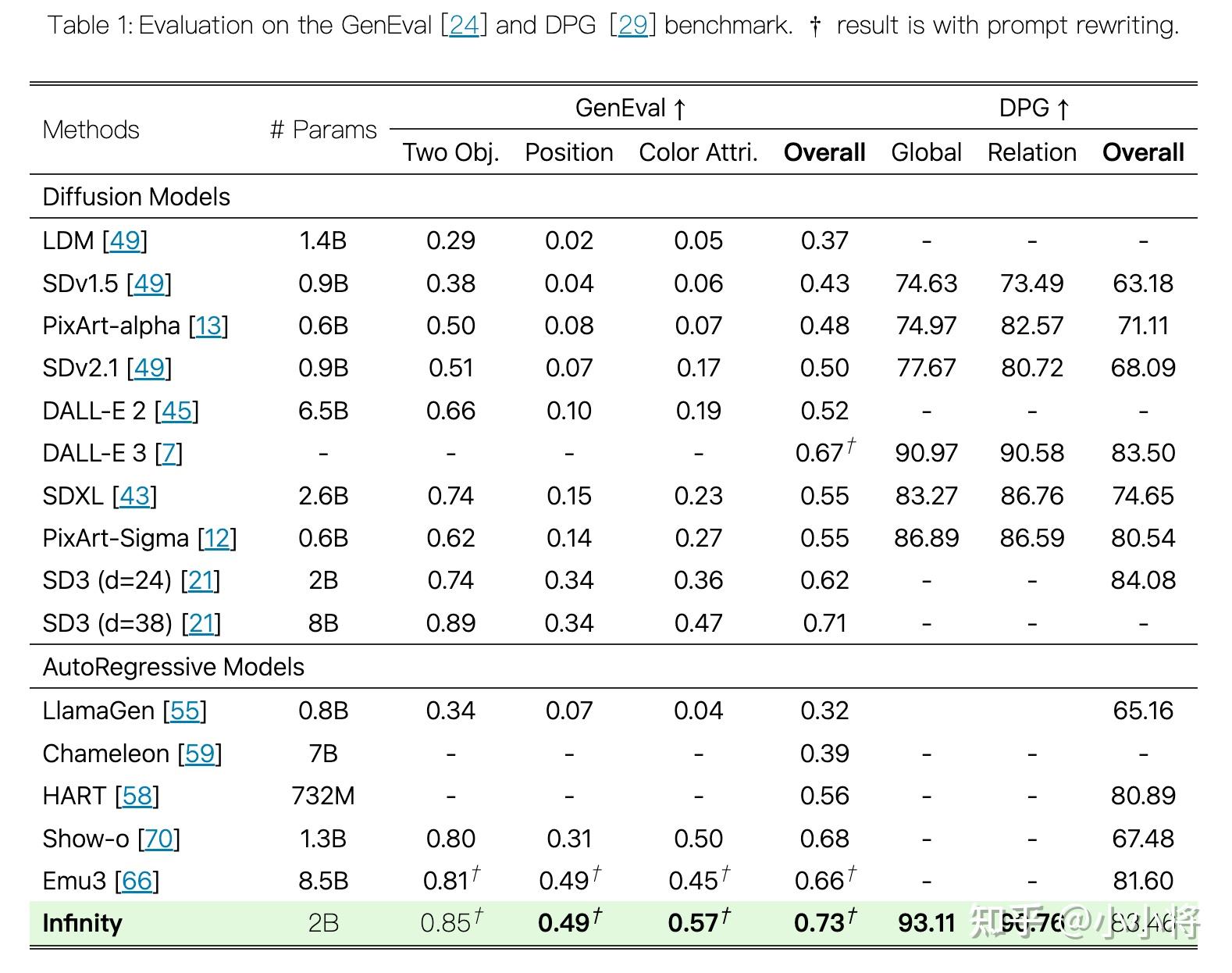
人工评测上,2B的Infinity优于2B的SD3-Medium。
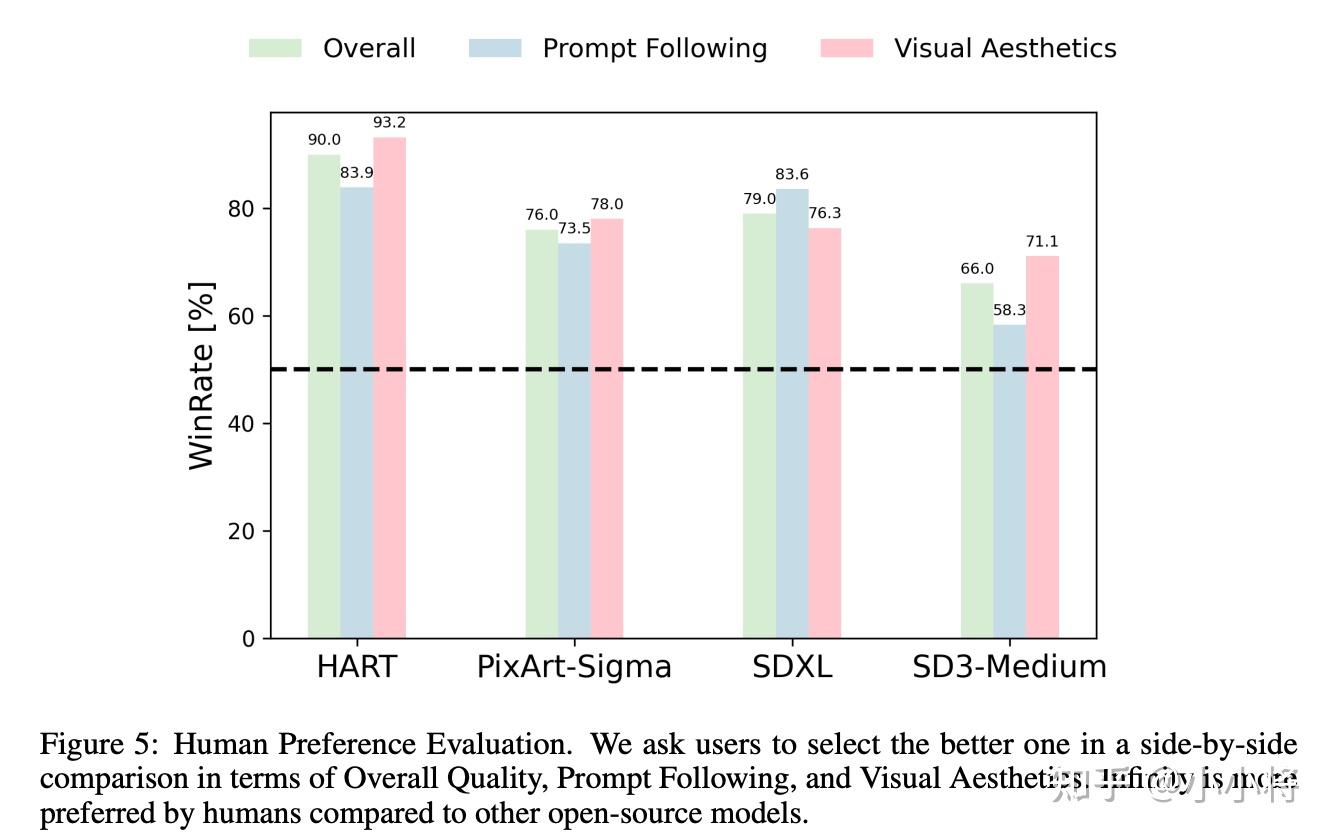
总之,从论文所展示的效果来看,Infinity确实超过了之前基于自回归的文生图模型的水准,而且可以达到一些SOTA的基于扩散的文生图模型效果,而且Infinity生成一张1024×1024图像只需要 0.8 s,比SD3-Medium快2.6倍。不过,目前Infinity模型还没有开源,所以还待实测效果。看到Infinity的效果,我想到了22年谷歌基于自回归的文生图模型Parti,当时20B的Parti效果超过了Imagen,不过Parti没有开源,而且后面扩散模型成为主流。但现在又有越来越多的基于自回归的文生图工作,也许不远的一天,自回归会取代扩散模型在图像生成领域的地位。
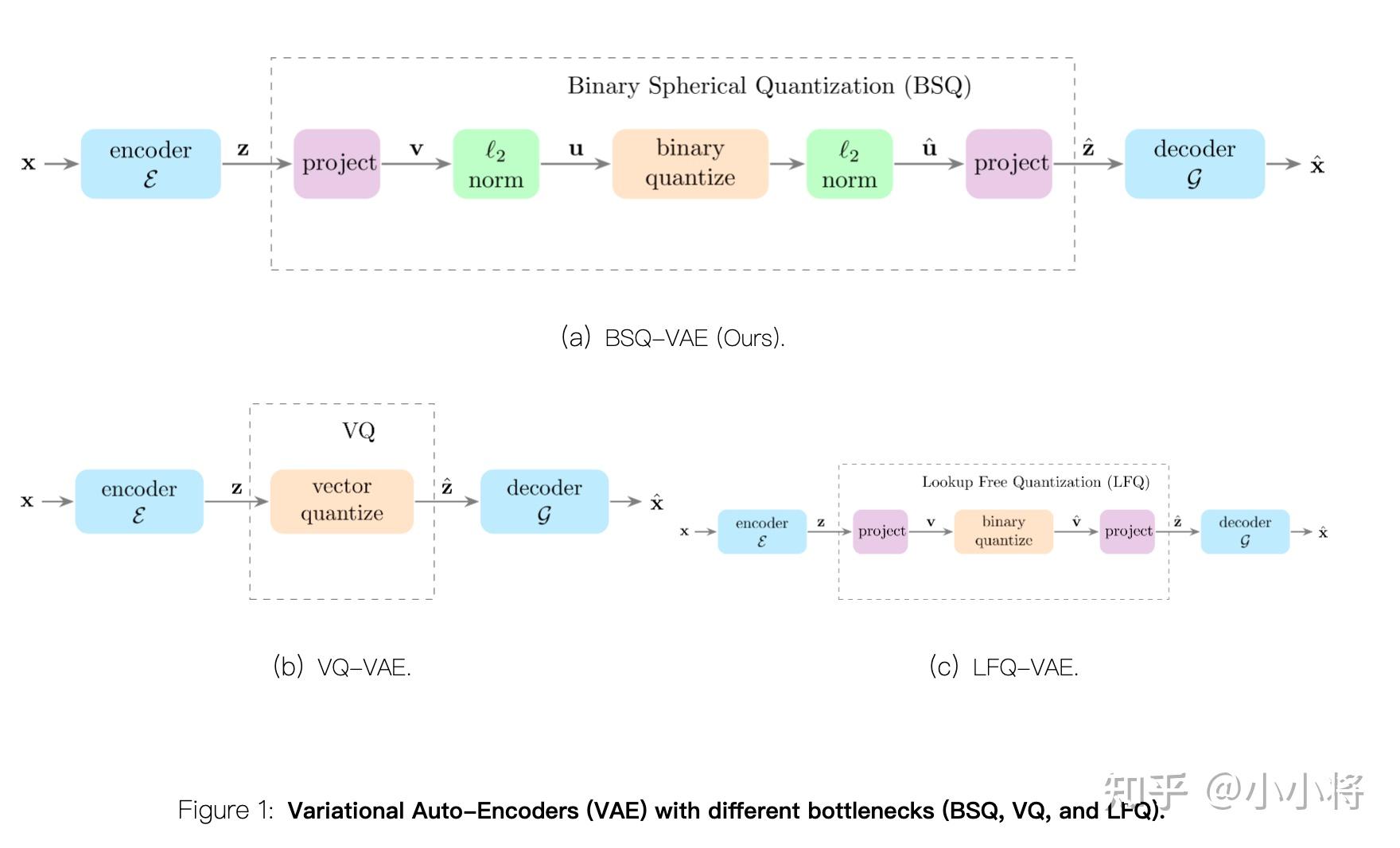
这篇文章我们主要是简单分析一下Infinity的模型实现细节。Infinity是VAR的文生图版本,所以这里先简单介绍一下VAR。VAR的tokenizer和VQVAE的区别是后者将图像离散成不同scale的tokens,具体是将一个连续特征量化为
个scale的特征
,最终的量化特征是所有scale的量化特征上采样后(双线性插值后加额外卷积)的和:
最后的特征送入tokenizer的decoder部分得到重建后的图像。在图像生成上,VAR也变成了next-scale prediction,简单来说,就是VAR是自回归地预测每个scale的tokens,之前AR每次预测一个token,而VAR每次预测一个scale的全部tokens(从低分辨率到高分辨率)。VAR的这种next-scale prediction对图像生成更友好,而且还可以加速。
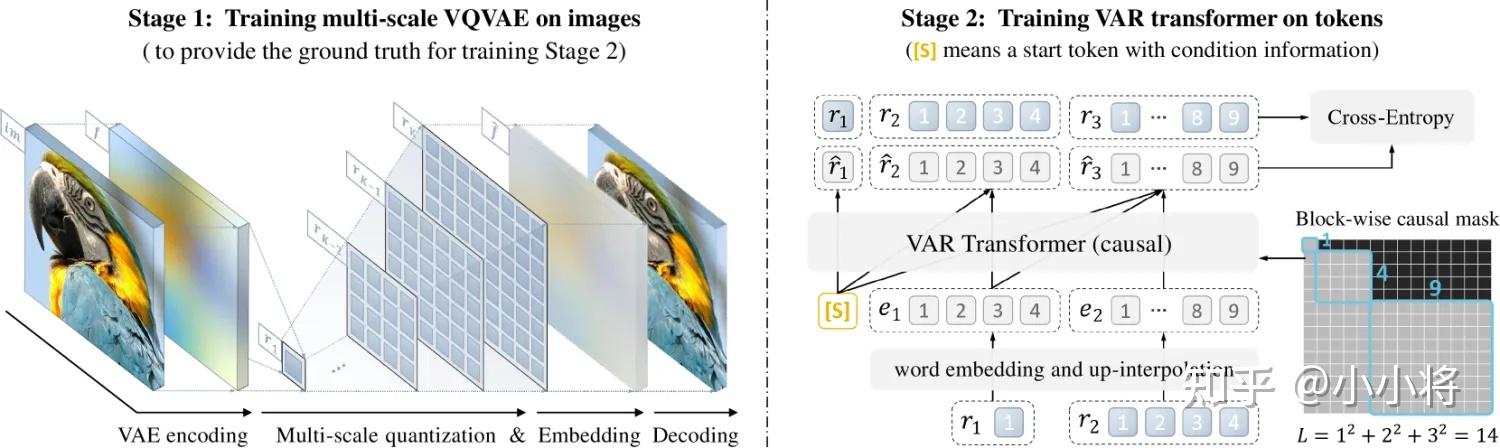
Infinity大致在架构上和VAR比较类似,包括一个VAR的图像tokenizer和一个Causal VAR Transformer来实现文到图的生成。这里是基于Flan-T5来提取文本特征,文本特征通过在Transformer中新增cross-attention层来插入,同时文本特征也会映射成一个特殊的向量作为Transformer的开始(预测第一个1x1的scale token)。
Infinity相比VAR的最大的变动还是在tokenzier,Infinity的tokenzier是采用了LFQ(Lookup-Free Quantizer)来量化特征,之前经典的VQ量化是需要去计算特征和codebook中所有code embedding之间的距离,并选择距离最近的code来量化。而LFQ是直接将特征按值的符号进行二值化量化:
可以看到LFQ不需要查表计算,所以是Lookup-Free,LFQ在之前的谷歌的MAGVIT-v2首先使用。如果我们的codebook的大小是,对于LFQ,code embedding的特征维度就是
,对于每个code,我们可以将其十进制先转成二进制,然后就可以根据二进制来得到二值化的code embedding,比如
,对于code=34,其二进制值为00100010,二值化的code embedding为[-1, -1, 1, -1, -1, -1, 1, -1]。所以,反过来,我们根据量化后的特征来得到对应的code:
从另外一个角度来看,之所以LFQ不需要查表计算,是因为LFQ的codebook的embedding是设计好的二值化特征,并可以找到一种特征和code之间的映射函数。
LFQ相比VQ的一个优势是增大codebook,图像生成能力也同步提升,而之前的VQ如果采用过大的codebook会导致图像生成效果劣化。
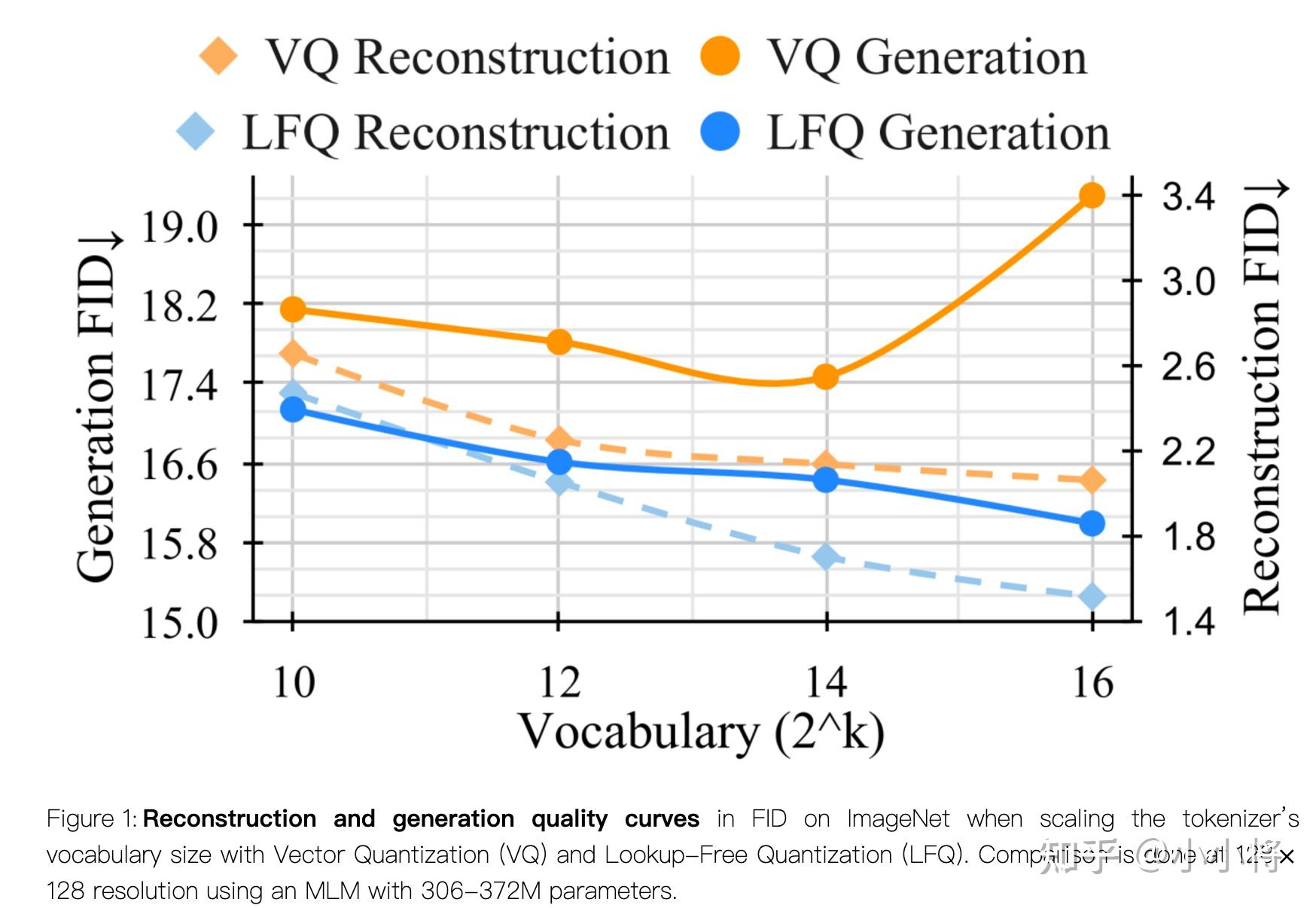
codebook越大,意味着tokenizer的图像重建能力越好,一个好的重建能力的图像tokenizer正是文生图模型所需要的。所以这里Infinity也采用了LFQ这种量化方式,除了LFQ,Infinity还考虑了LFQ的变种BSQ:
BSQ和LFQ的一个区别是将特征二值化为和
,这里
是特征维度,所以量化的特征是单位向量。更具体地说,BSQ会对量化前特征和量化后特征做一个l2 norm,从而让量化前后的特征都变成单位向量。
为了保证codebook的利用率,训练LFQ的tokenizer的时候还会加上一个熵惩罚:
这里的是指的特征
分配到codebook的分类分布,所以第一项
其实是约束每个
要确定性分配到codebook的一个code(分布的熵的期望要小),而第二项
是希望
所分配的code能均匀分布在codebook中(分布的期望的熵要大)。要计算这个分布
,我们需要计算训练batch中的特征
和整个codebook每个code embedding的点积来得到logits,当codebook很大的时候,会出现OOM。但是BSQ由于
和code embedding都是单位向量,熵惩罚的计算复杂度可以简化为
,而LFQ的计算复杂度是
。当codebook很大的时候,LFQ会OOM,但是BSQ不会:

所以Infinity最终选择BSQ来量化。如果VAR tokenizer+BSQ,当codebook增大的时候,其重建效果(r FID)能超过连续的VAE:
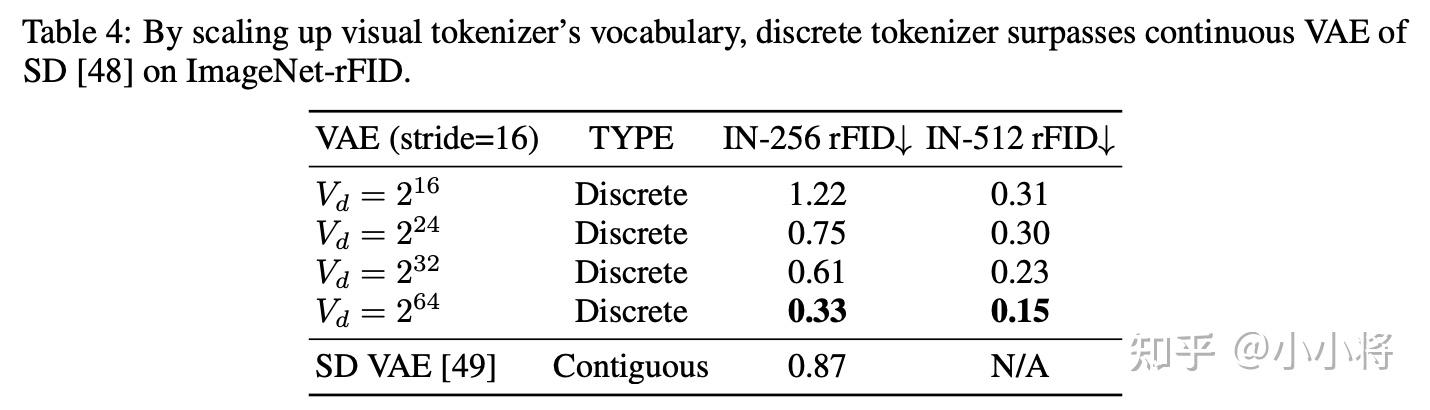
最终Infinity设定的codebook大小是,此时已经超过int32值的范围,所以这里说是一个词表无限大的tokenzier。这也是模型之所以叫Infinity的原因(其实并不是无限大)。
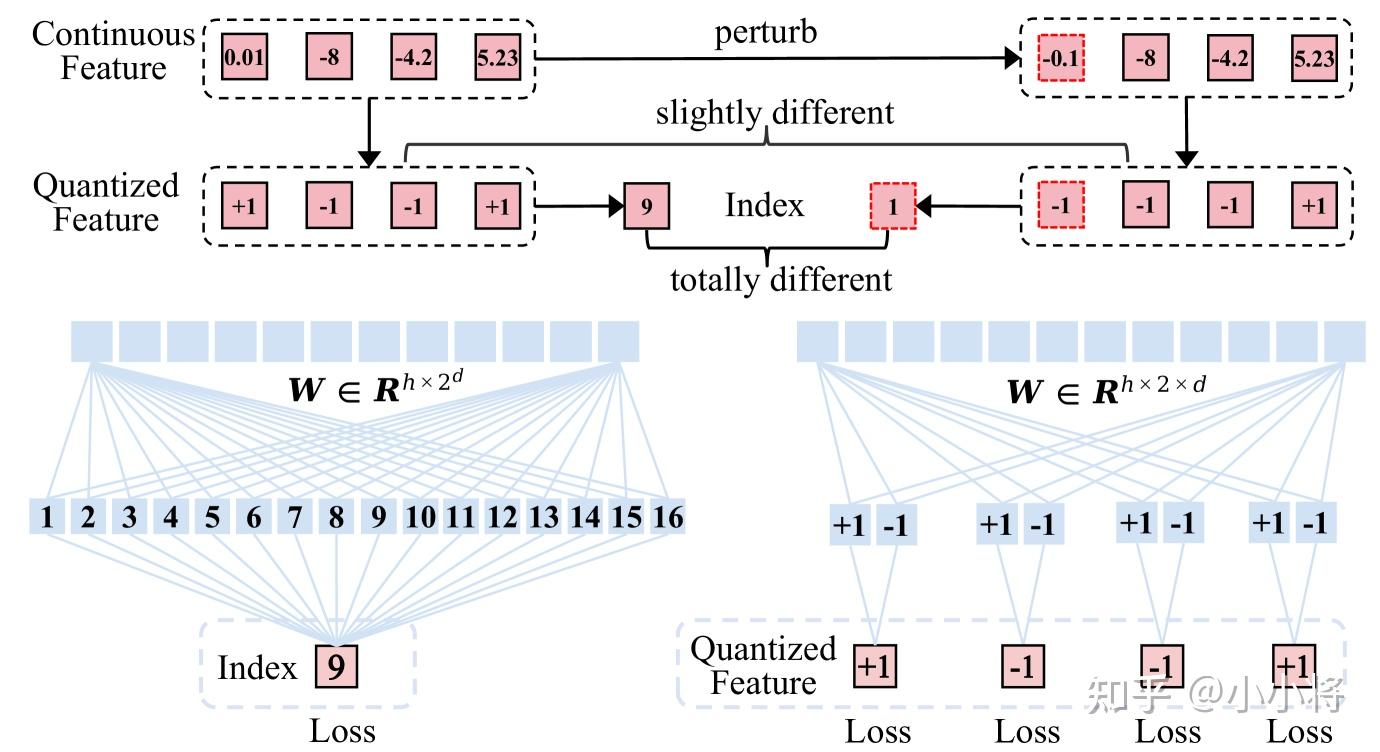
当codebook变大之后,用于自回归生成的分类头也会非常消耗显存。比如词表,transformer的特征
,这个时候分类头的权重矩阵
就需要8.8T的显存,这是目前的GPU所无法承受的。这里采用的优化策略是采用
个二分类来并行预测code的二进制值,这里的
,所以对于上述情况下,这样优化后会节省99.95%的参数。而且,用
个分类器预测二进制值也更鲁棒一些,比如连续特征的某个接近零的值发生动变,这虽然只会影响一个二进制值,但是会导致对应的code发生大变。
对比实验发现这种变动不仅节省了显存,同时也提升了生图性能:

还有助于提升生成图像的细节:

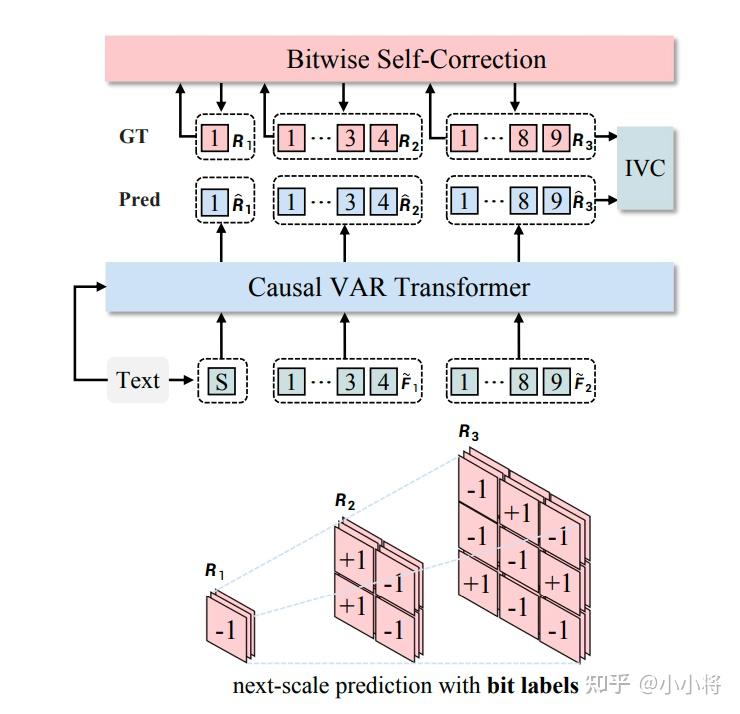
除了tokenizer的优化,Infinity还设计了一种训练过程中数据增强策略Bitwise Self-Correction(简称BSC)。BSC主要是为了解决AR模型训练过程中teacher-forcing来导致的训练和测试不一致问题。具体来说,对于VAR训练,每个scale的输入是根据GT图像计算的前面scale的累积特征,但是实际推理的时候,我们并没有GT图像,而且前面的scale预测也会出错,为了提升模型的容错能力,这里设计了一种BSC的数据增强策略。具体来说,我们会以一定概率翻转量化特征的某个位置的值,比如从1变成-1,特征 从变成了
,后者是包含一定的错误。然后我们重新计算前
个量化特征之和得到
,这个包含错误的特征用来作为下一个scale预测的输入,但是监督的GT没有变,所以模型能够学会自动纠错的能力。
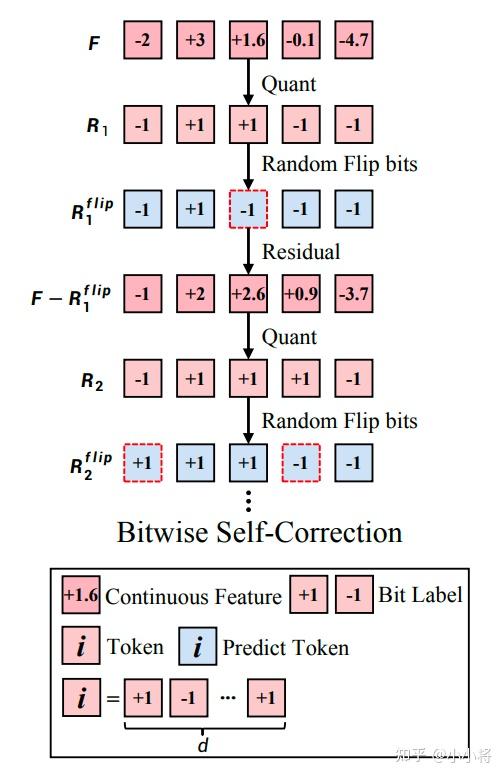
除此之外,这里还会把 的错误传导下去,意思说我们会重新量化来得到下一个scale的量化值
。具体的算法逻辑如下所示:

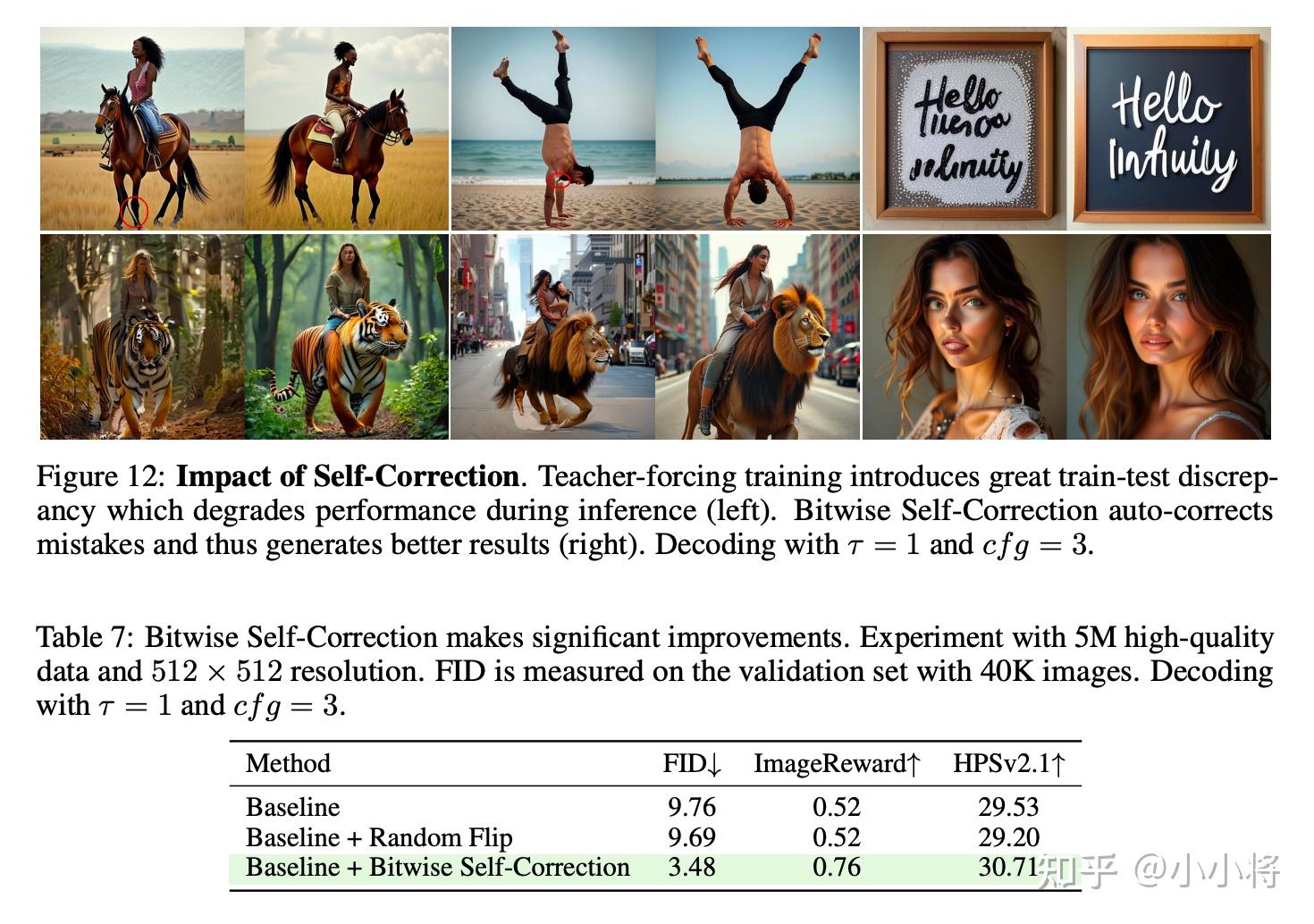
实验对比,BSC确实能够提升生图效果:
Infinity还为了支持变分辨率生成,也采用了分桶的多尺度训练策略以及2D rope位置编码。训练过程也采用多阶段训练策略:256 -> 512 -> 1024。这些应该都是常规策略。
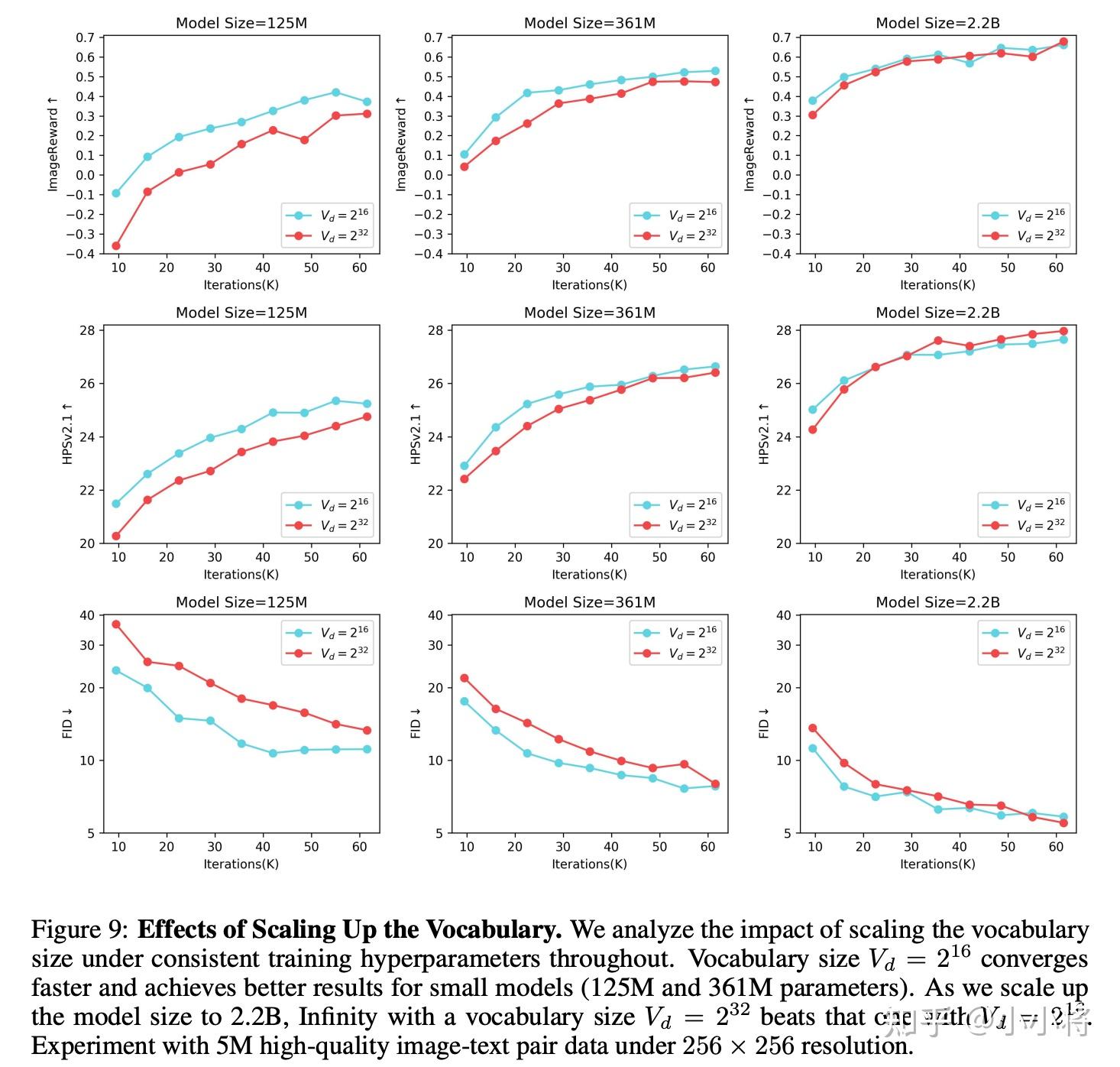
最后,我想说一下Infinity的scaling实验,因为这个对于AR模型确实是比较重要的。首先是codebook的增大,当增大codebook,小模型上表现不出优势,但是当增大模型时,大的codebook就会显现出来优势:
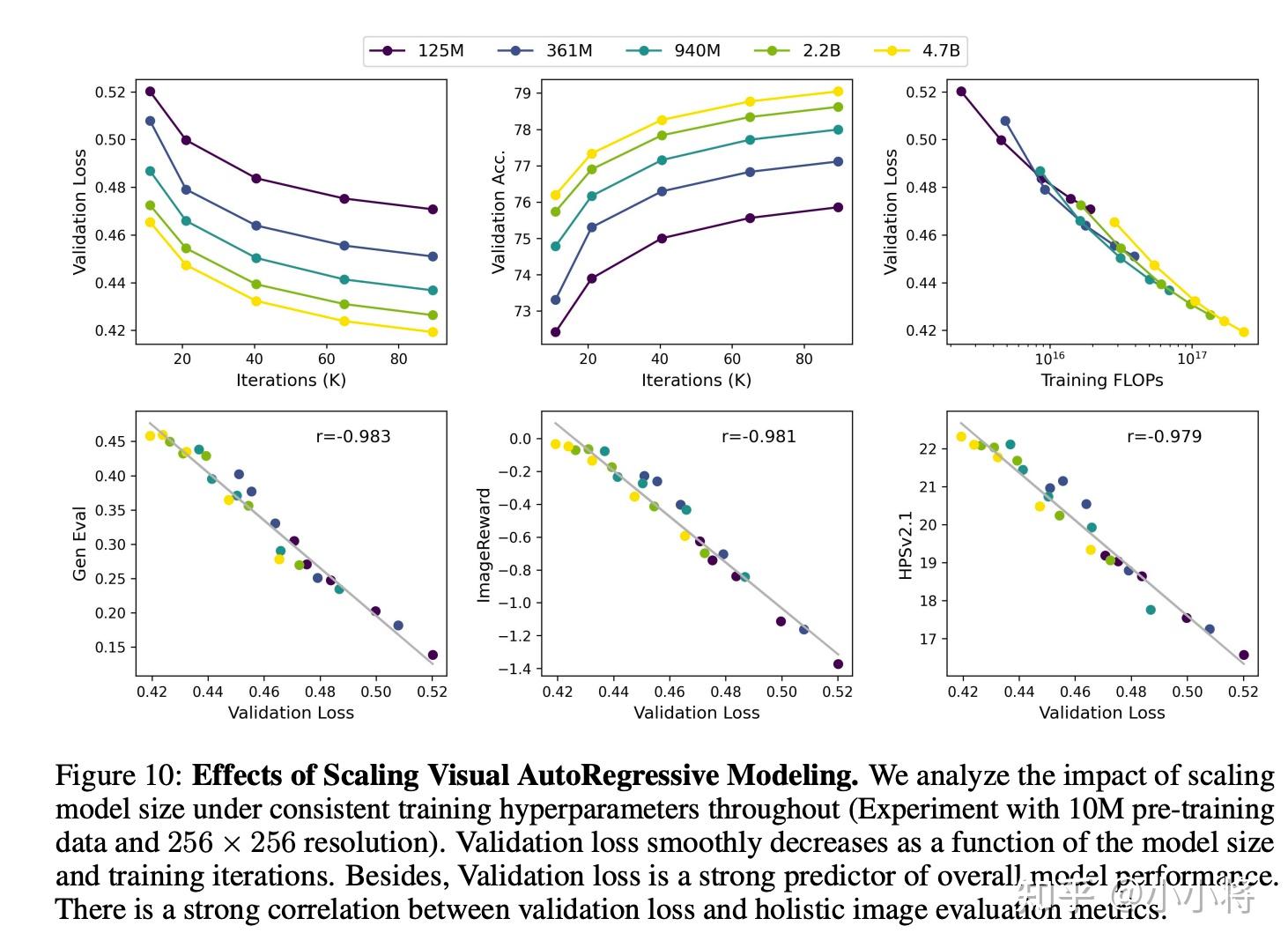
另外就是模型参数的scaling,可以看到这里表现了比较好的模型scaling能力,增大模型参数,验证集loss稳步下降,而且验证集loss和生图的评估指标有很强的正向关。
现在的Infinity参数量只有2B,如果未来变得更大,性能应该有进一步的提升,所以感觉还是有很大的潜力。
参考
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
- Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
- Image and Video Tokenization with Binary Spherical Quantization
- Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
- Open-MAGVIT2: An Open-Source Project Toward Democratizing Auto-regressive Visual Generation