如何评价 DeepSeek 的 DeepSeek-V3 模型?
发布时间:
2025-01-28 22:01
阅读量:
21
营销得哪里厉害,去试用了一下。
结论:垃圾一个,实测只能给0分,但是营销力度很大,惯犯了。
自己看吧。



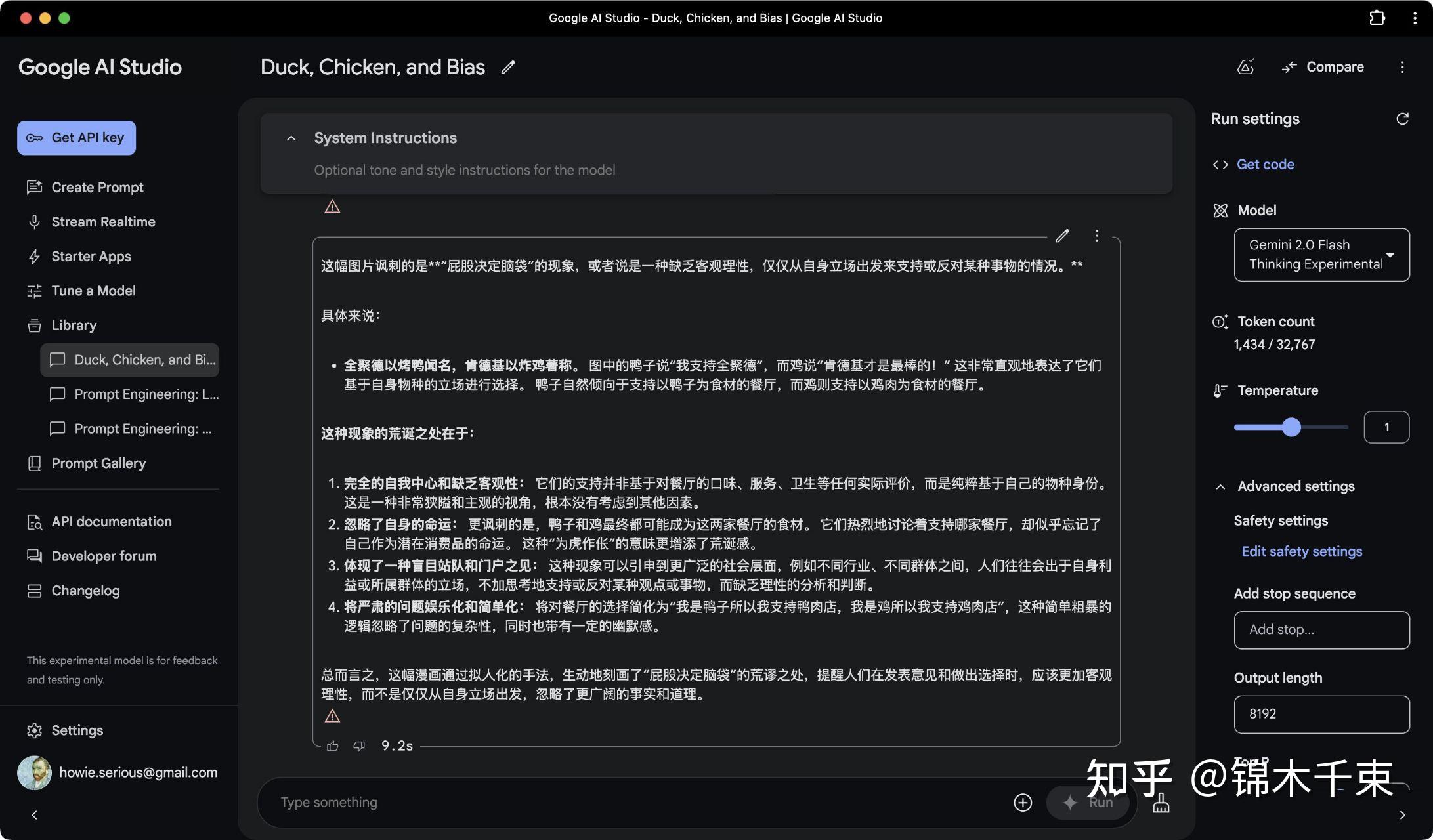
幽默与讽刺,在判断LLM智能水平,屡试不爽,简单明了。
这个测试案例中,我提的问题是:“这幅图片,讽刺的是什么现象? 这种现象的荒诞之处在哪里?”
目的是看 LLM 能不能直截了当,精准点名讽刺对象、荒诞之处。
因为很多 LLM 可以胡说八道,生成一堆看起来有模有样实际上不及格的内容。这种现象,对于非幽默讽刺的问题,人类很多时候都是很难识别和判断的。但是,在讽刺幽默问题上,结果的质量非常好判断。
测试打分如下:
- o1 得分 100 分:直击本质;
- gpt-4o 80 分:认识到了本质,也基本没有偏离;
- gemini 2.0 flash thinking ,最多 60 分,实际不及格:错误理解了本质,但也谈到了“忽略自身命运”,但胡说八道的程度也不低;
结论:在语言理解上,gemini 系列模型和 gpt、o1 还有本质差距。普通人日常使用,尤其是语言理解场景,还是要以 ChatGPT 为主力。
至于deepseek,很不幸的在本轮测试中只拿到了0分,鉴定为营销圈钱意义远大于实际作用与水平。

END