谷歌发布 Gemini 2.5 Pro 模型,称其是一个「思考」模型专为复杂任务打造,它有多强大?
Gemini 2.5 Pro Experimental 03-25
一句话总结:Google也要给OpenAI上强度了
24号DeepSeekV3教育OpenAI什么是好用又便宜的基础模型,25号Google也来给OpenAI上强度,什么是免费又好用的推理模型。
2.5Pro作为一个推理模型,速度还是挺快,测试的平均耗时控制在50秒。这速度虽然比不上自家flash thinking,但在一众推理模型里算快的。
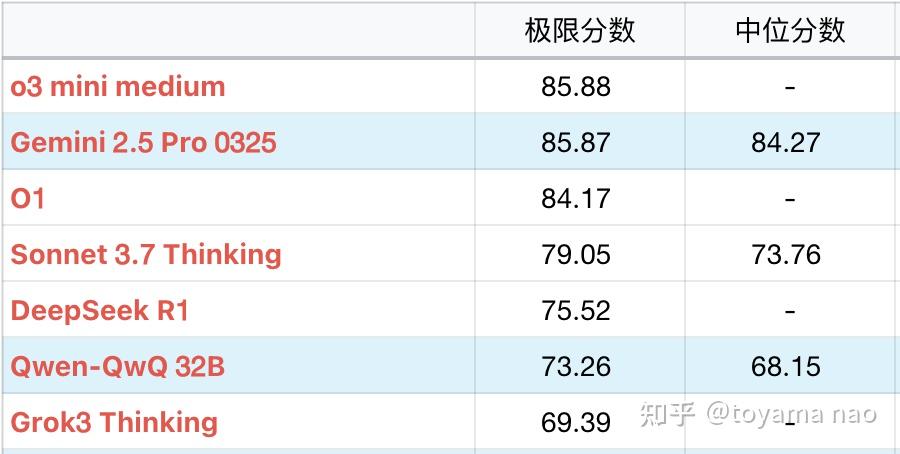
在这个速度上,2.5Pro的成绩达到了85分的极限分,并且其稳定性相当好,中位分仅低1分(2%)。绝大部分题目在多次测试中都可以输出相似答案。这简直像个奇迹,之前稳定性最好的Sonnet3.7 中位分也要低6%。
测试时笔者选择在半个小时后跑第二遍,尽量避免工程上缓存造成的稳定假象。
具体来看,2.5Pro在很多题目上的表现可圈可点,比如#25算24点,他不但全对,并且每个算式还尝试了多种解法。其他计算题如#10水果热量,#22连续计算,得分都很高,2.5Pro很清楚自己在算什么,几乎没有幻觉。
在高难度题目上,之前大部分推理模型折戟,仅o1/o3能得分,这次2.5Pro也拿到不少分。如#23解密游戏, 2.5Pro快速找到了思路,一举突破。#24数字规律非常考验人类直觉,2.5Pro已经找到了一部分规律,但没能全对。对比其他低阶推理模型在这道题上几乎是盲猜。
但2.5Pro也不是没有问题,他的字符幻觉就比o3来的更多,如#11岛屿面积,#18字符迷宫,o3分数都更高。而2.5Pro的表现就很差。#30日记整理对输出有字数要求,2.5Pro也是目前输出字数远超要求的模型。
总体上,2.5Pro解题很有章法,比较少靠暴力穷举,对于难题和中等题目,基本都能一次性找对思路,知道该推理什么,计算什么。丢分也主要是数学上的细节,字符幻觉等大模型传统劣势。
目前这个形势,OpenAI压力确实非常大。