如何看待 Llama 3.1 ?
近日,英伟达开源了大语言模型Nemotron-70B,在多个基准测试中,这个基于Llama 3.1训练的模型超越了GPT-4o和Claude 3.5 Sonnet这些最先进AI模型。
一如既往,硅基流动SiliconCloud第一时间上线了Llama-3.1-Nemotron-70B-Instruct。
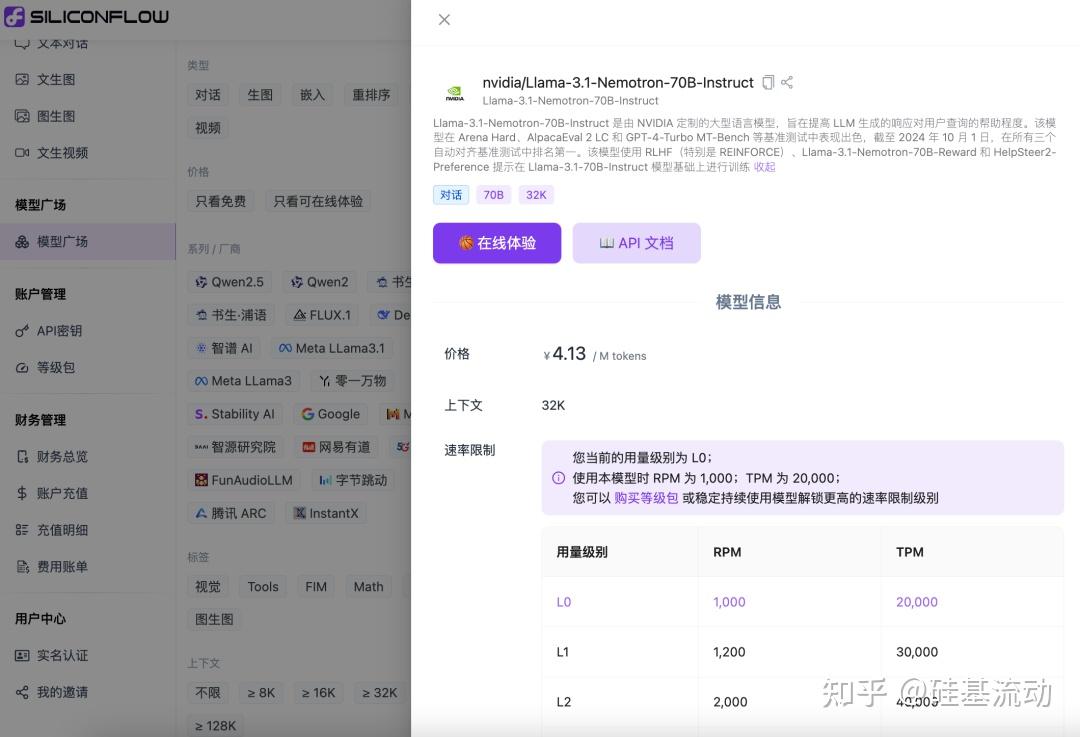
感受一下Llama-3.1-Nemotron-70B-Instruct在SiliconCloud上推理加速后的效果。
Playground传送门(需实名认证)
https://cloud.siliconflow.cn/playground/chat/17885302599
API文档https://docs.siliconflow.cn/api-reference/chat-completions/chat-completions
与其他各类开源大模型一样,开发者在本地运行Llama-3.1-Nemotron-70B-Instruct模型有较高部署门槛与成本。现在,SiliconCloud上线该模型后,免去了开发者的部署门槛,并在开发应用时轻松调用相应的API服务。
更重要的是,SiliconCloud平台上的Llama-3.1-Nemotron-70B-Instruct输出速度极快,能为你的生成式AI应用带来更高效的用户体验。此外,与平台上其他70B模型的价格保持一致,Llama-3.1-Nemotron-70B-Instruct仅需¥4.13 / M tokens。
平台还支持开发者自由对比体验各类大模型,最终为自己的生成式AI应用选择最佳实践。
模型评测表现及亮点
基于Llama-3.1-70B-Instruct,Llama-3.1-Nemotron-70B-Instruct使用RLHF(特别是 REINFORCE)、Llama-3.1-Nemotron-70B-Reward和HelpSteer2-Preference提示进行了训练。
基于强大的70B参数架构,它利用增强的多查询注意力和优化后的Transformer架构设计,提供更快计算速度,同时不牺牲准确性。
截至 2024 年 10 月 1 日,Llama-3.1-Nemotron-70B-Instruct在Arena Hard、AlpacaEval 2 LC 和MT-Bench(GPT-4-Turbo)这三个自动对齐基准测试中排名第一。
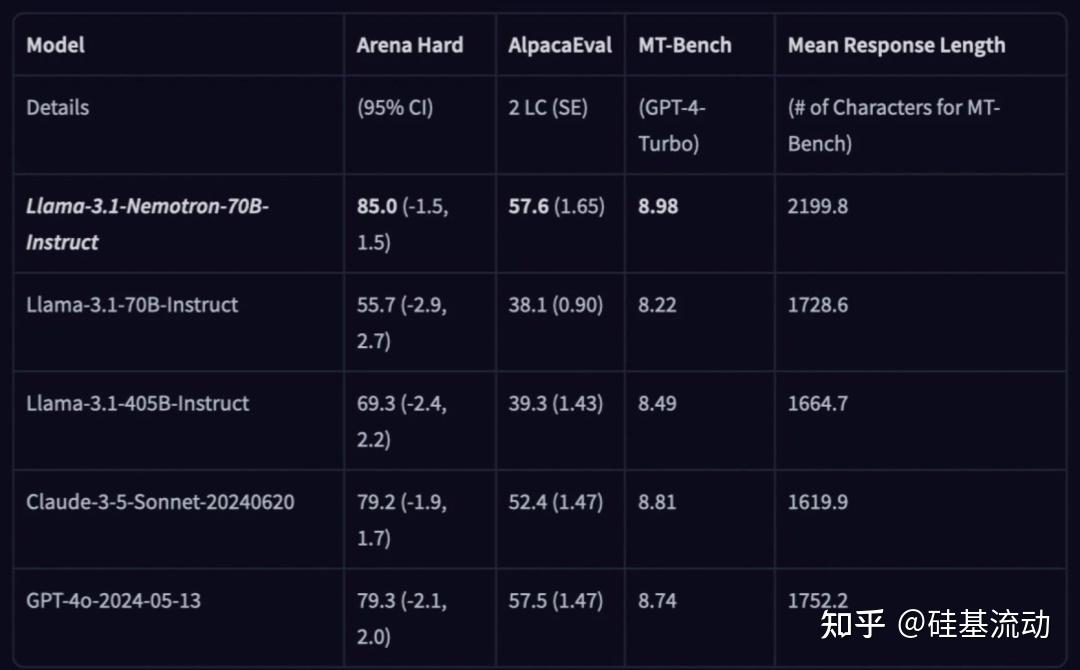
Token工厂SiliconCloud
Qwen2.5(7B)、Llama3.1(8B)等免费用
作为集合顶尖大模型的一站式云服务平台,SiliconCloud致力于为开发者提供更快、更便宜、更全面、体验更丝滑的模型API。
除了Llama-3.1-Nemotron-70B-Instruct,SiliconCloud已上架包括Qwen2-VL、InternVL2、Qwen2.5-Coder-7B-Instruct、Qwen2.5-Math-72B-Instruct、Qwen2.5-7B/14B/32B/72B、FLUX.1、DeepSeek-V2.5、InternLM2.5-20B-Chat、BCE、BGE、SenseVoice-Small、Llama-3.1、GLM-4-9B-Chat在内的多种开源大语言模型、图片生成模型、代码生成模型、向量与重排序模型以及多模态大模型。
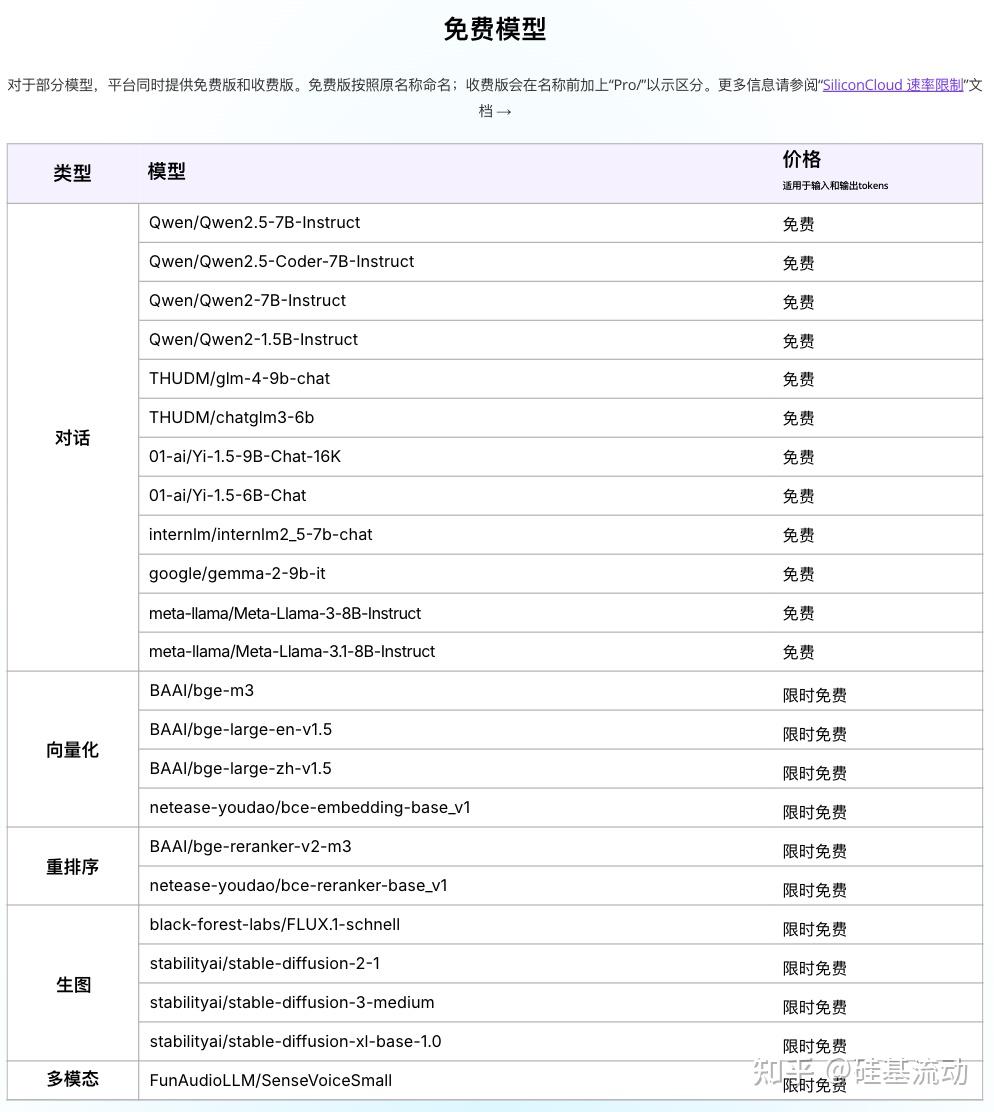
其中,Qwen2.5(7B)、Llama3.1(8B)等多个大模型API免费使用,让开发者与产品经理无需担心研发阶段和大规模推广所带来的算力成本,实现“Token 自由”。
让超级产品开发者实现“Token自由”
邀请好友体验SiliconCloud,狂送2000万Token/人
邀请越多,Token奖励越多
SiliconCloud