DeepSeek 冲击全球算力,A 股寒武纪跌近 10%,纳指期货跌近 2%,后续走势会怎么样?
今天NVDA暴跌似乎是印证了前段时间的一个很流行的观点:DeepSeek打破了堆算力的神话,证明不需要那么高的算力也能做出来非常好用的大语言模型。但是我觉得其背后还有更加深刻的原因。
因为DeepSeek只是证明了要达到近似于o1的水平,只需要十分之一的成本就可以。这个对于算力的未来其实是可左可右的,往悲观说,目前算力的需求被过度夸张了;往乐观了说,现在算力足以堆起来更强大的AI。市场的反应还应该是根源于后者不太乐观。
首先,目前4o,包括o1的能力的提升,很大程度上是来自于对训练样本的精炼和对思维链(CoT)这个技巧的压榨。思维链有效的平滑了推理的流程,降低了推理的难度,让大语言模型可以沿着自己生成的链条继续推理,生成正确的答案。也就是说,就模型「原生」的推理能力来说,提升并没有那么显著。
但是,靠着思维链和高质量合成数据是不可能无限提高模型能力的。随着思维链的延长,模型在其中任何一步出错的概率也在增加,并且「如何把一个复杂问题有效的延展成一个思维链」本身就成为了一个推理问题,这个能力也会受到模型原生推理能力的限制。
在kimi最新的报告[1]里面提到:
Notably, although the larger model initially outperforms the smaller one, the smaller model can achieve comparable performance by utilizing longer CoTs optimized through RL.
通过强化学习,可以让小模型通过更长的思维链来达到大模型的精确度。目前o1和r1也都是通过这种方式增强的能力:
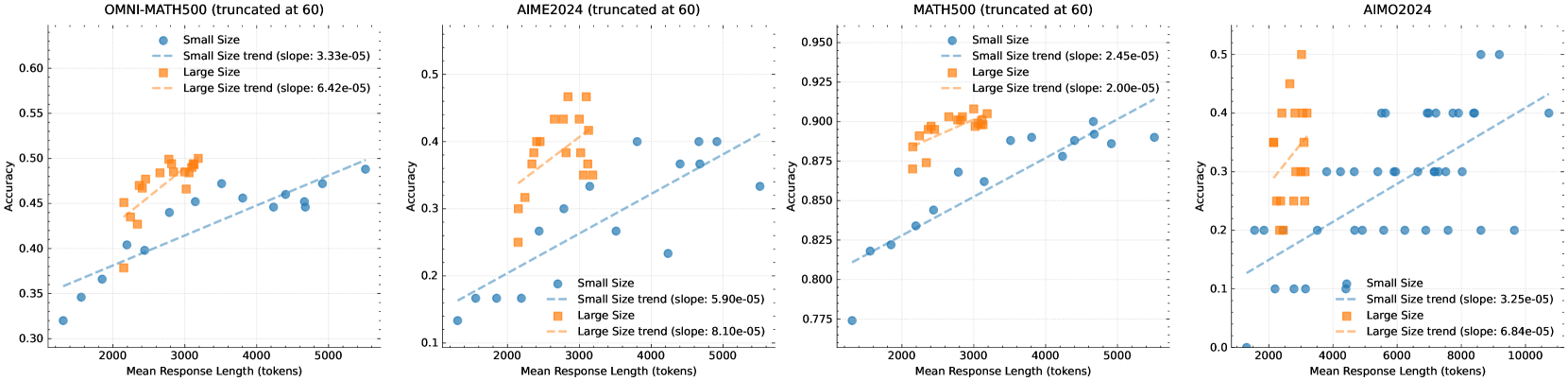
虽然我们现在知道思维链对于大模型来说似乎更有效,上图的斜率也多少说明了这一点,但是我们现在不清楚的是,这种增长是不是可持续的。可以预计到在将来,我们总会到这么一个点:需要判断AI的推理能力在当前的大框架下是否还能够进一步的本质提高,还是说需要不断的通过「CoT/MoE/MCTS...」的方式来慢慢的推进AI的能力。如果是后者,那意味着这个领域就基本稳定下来了。
在DeepSeek之前,所有的头部大模型企业都觉得现在继续做大算力探索就好,距离我们需要进行这种判断的时间点还有一段时间,但是DeepSeek R1证明了硬件的潜力还远远没有发掘尽,就现在的算力规模下,我们就需要做出上述的判断。这相当于把未来的一个决策时间点拉到了现在,降低了想象空间,增大了市场的不确定性。我觉得这个才是短期的市场情绪之外,DeepSeek所带来的一个根本利空。