能大致讲一下 DeepSeek 的原理吗?
前言:为什么写这篇文章
张涛关于DeepSeek的分享非常精彩,我一口气看完,深受震撼。主要有两个点:
第一,万事开头难,之前我也碎片式了解一些大模型原理、基建层面的知识,但是碎片化的学,又经常遇到各种语言、专业程度不一致的内容,导致学起来挺吃力的,有些概念长期处于似懂非懂的状态。没想到跟着他一个概念一个概念捋下来,自己好像上了一堂专业通识课,过去似懂非懂的概念或多或少变清晰了,甚至也追根溯源翻了几篇论文,模模糊糊能看进去了。
第二,DeepSeek真是在进行勇敢者的游戏,别管懂了多少,看着DeepSeek一路披荆斩棘的过程,自己也血脉贲张、感同身受。比亚迪出了一本书叫《工程师之魂》,这个名字其实取给DeepSeek这帮人是更合适的,因为DeepSeek做的事情更简洁、精粹,有一种机械降神的美感。
尽管张涛的内容已经非常通俗易懂,讲解也引人入胜,但是那篇内容主要面向真格基金的成员,多多少少对大模型的基础概念还是有一定了解。我在看视频的过程中,也要经常暂停下来或倒退回去,检索下相关概念。
最好的致敬是学习,这也是我写这篇文章的目的。
这篇文章的主要受众可能是:工作中不怎么接触大模型,但是对大模型感兴趣、或者未来有可能会接触到大模型的非专业人士,尤其是产品经理。
这篇文章希望起到的价值是:
- 技术祛魅。我们不要轻易对技术概念产生畏难心理,咱们多多少少都能理解一些其中的概念,多多少少都能翻点算术书或者英文论文。我们不需要自己手搓大模型,只要多少意会一点,也有收获。
- 定性理解。我们可能不需要很准确地知道里面每个计算是如何发生的,但是可以定性地理解一些技术概念的原理,进而对大模型做什么更合适、做什么容易有局限产生自己的判断,而这些判断对于上述受众来说可能是更有价值的。
这篇文章可以看作是张涛分享原文的注释,而张涛的分享核心篇幅也是基于一篇Sebastian Raschka的文章展开的,我维持相同的结构——跟着DeepSeek-R1的诞生过程,了解大语言模型的一些基础概念。
当然,对于理科背景的同学,我仍然推荐大家直接阅读张涛的原文和原视频。
另外,强烈感谢本文的技术支持LXM与兽哥的审稿,提出了大量的修改意见~
V3:推理模型
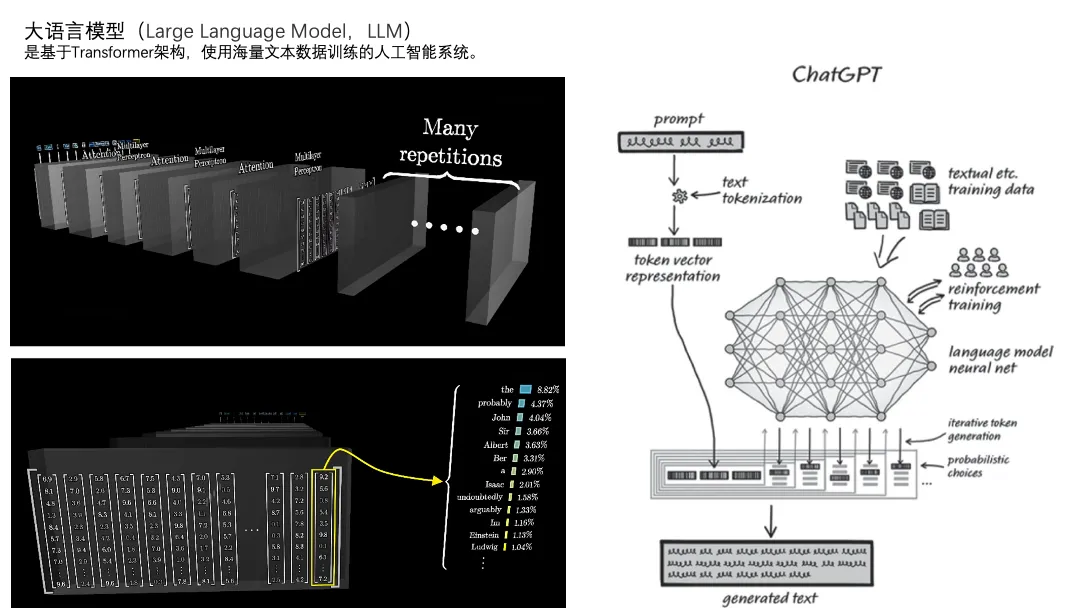
咱们讲的大模型准确来说是大语言模型,其中最核心的部分是transformer架构和基于无标注数据的预训练方法。
写这一页的时候可让我挠头了半天,考虑要不要把里面一些原理也讲一讲,例如embedding、KQV、注意力机制等等。因为了解了这些基础概念,对于后面理解一些偏工程的、实现的概念时,帮助很大。但是如果我是一个工作中不需要直接接触模型的人,或者文科背景的,看到这一堆线性代数的内容可能会非常头疼,且用处不大。
本着定性理解而非定量掌握的目的,我们只需要了解这么几件事:
大模型跟你说话的过程,本质上是它把你说的指令(提示词prompt)中每一个字(token,当然1个token也有可能是一个词)转换成一堆数字(向量),然后用一层一层的神经网络反复对那些数字计算,最后得到下一个字出现的概率,然后它不断把再下个字算出来。
上面提到的神经网络对数字计算,计算的系数就是参数。一个模型有很多层的神经网络,每层神经网络有非常多的节点,每个节点还有不同的运算和对应的参数。我们讲的大模型的“大”,就是指参数量巨大。
我们一般会提到大模型有训练和推理两个阶段。
训练阶段就是指的用海量数据,把模型里面这一大堆参数的值算出来。数据巨大、计算时间长、需要的资源多,DeepSeek-V3有6710亿(670B)的参数量,单次训练用了2000张H800的卡,花了557万美元,但这已经是行业内称奇的“低成本”了。
推理阶段指的是用户输入了内容之后,大模型用已经训练好的这一大堆参数和算数方法,算出答案的过程。我用纳米ai的deepseek满血版,一般是几秒到几十秒不等,这就是推理的过程。推理的时间和成本显然是远低于训练成本的,但仍然不容忽视,特别是针对大用户量的、成本和效率敏感型的业务。
好吧,如果我是个文科生,掌握这些基本就够了。但我仍然推荐大家尽量自己看一些深入浅出的原理性内容,比如3Blue1Brown关于transformer的视频和Andrej Karpathy的3小时科普视频。(链接在最后)

这里我们必须强调一个关键认知,尽管很多内容上会讲大模型能够理解和生成自然文本,但是我认为这里的“理解”跟我们常规意义的“理解”不是一回事,大模型更像是从概率上理解两个词(这里的词也不一定是自然的词,可能是人类语言里的半个词)之间关联度的高低(注意力机制)。
所以我会这么形容大模型:它没有真正理解事物,而是通过上下文内容计算下一个概率最高的词。
在下文中也会反复提到大模型的本质还是猜。大模型虽然是所谓的没有具体的下游任务,通过提示词prompt来完成,事实上所有大模型的下游任务都是next token prediction,本质逃不开概率。
这一部分我的叙述主要集中在预训练阶段,实际上大模型所展现出来的“理解能力”还包含了和人类对齐的过程(后训练)。
另外,所谓的“幻觉”是如何产生的,也与此有关:大模型预训练的语料里面包含巨大的信息(有种说法是人类迄今为止所有的文字都已经被大模型学过了),必然包含错误的、前后矛盾的信息,要么是学错了,要么是学歪了,总有可能产生偏差,要么是学完了不知道自己学到了开始瞎编,进而说出“太阳从西方升起”的话。

既然大模型是猜词,那么就有“直接猜结果”和“一步一步猜”。
拿上图的例子来说,这种分步骤计算的问题,左边就是直接猜结果,右边是一步一步猜。
实际上我们在写提示词的时候,怎么一步一步猜,也可以定义得更详细、更具体一点。比如上图右边,为什么分成这四步,也是大模型自己猜的,我只要求他分步骤运算。我也可以要求他按照【复述问题】、【写“解:”】、【列方程式】、【求解方程式】、【写“答”】的步骤进行。
不仅仅是数学题,可能帮我规划下明天穿什么衣服也要分步看下明天天气和我有哪些干净衣服,这种一步一步推理的过程就是思维链CoT。
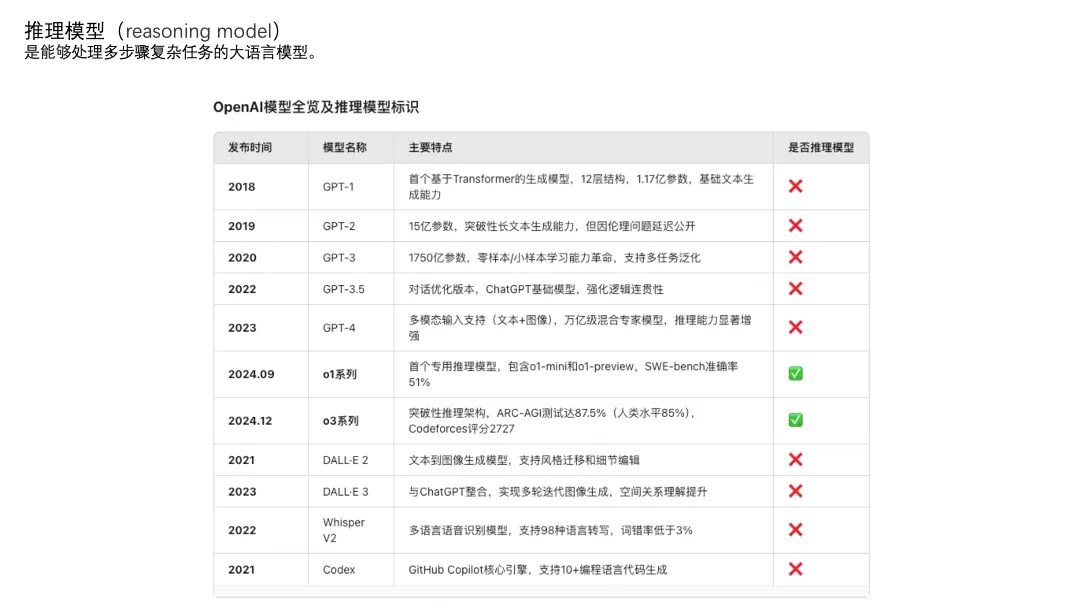
上面展示的思维链的案例,还需要用户在指令里面要求大模型“一步一步来”。如果在模型的训练过程中通过某种方式,让模型自己具备了一步一步思考的能力,而不是直接去猜答案,这种模型就是推理模型。
最早的推理模型是openai在2024年9月发布的openai o1。
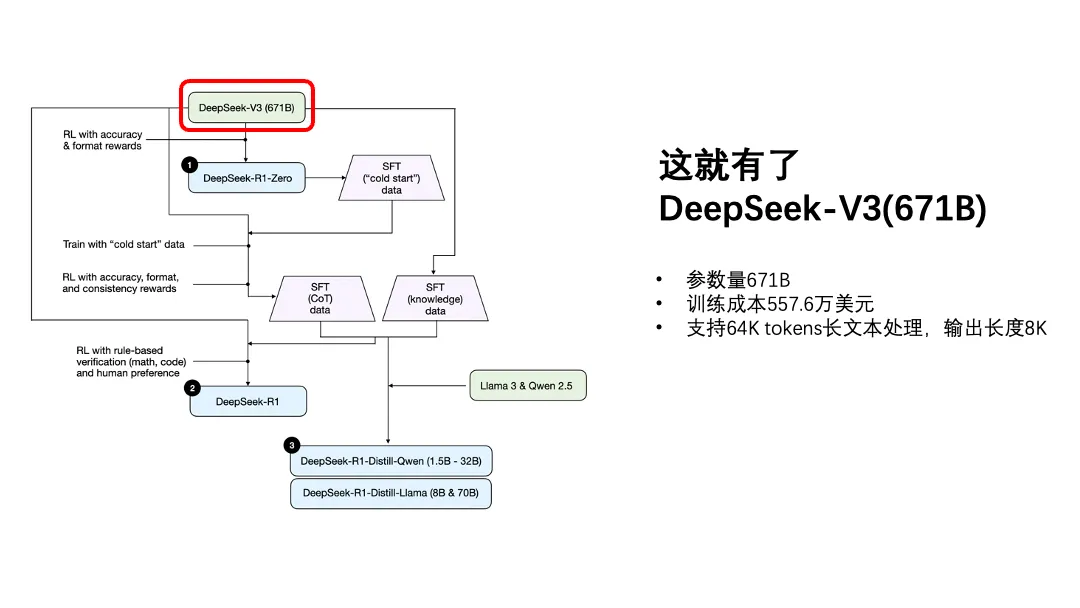
o1发布几个月之后,我们就见到了DeepSeek第一个被大众熟知的模型DeepSeek-V3,它是一个有着671B参数量的推理模型。V3的设计和训练过程妙趣横生,但是要理解其中精妙之处,最好还是补充一些transformer相关的知识。考虑许久我还是放弃在这篇文章中讲那些内容了。
作为文科生,我们只要知道DeepSeek-V3是个参数量巨大但是训练成本相对来说并不高的推理模型,性能堪比GPT-4o,特别擅长处理长文本、代码、数学这类的任务。

但是,必须强调一点,虽然叫“推理模型”,我倾向于认为大模型仍然不能理解“理”,只是从直接猜结果,变成了一步一步猜。当然,每一步应该怎么猜,也是需要猜的。
这就上升到哲学、脑科学的范畴了,兴许人类自以为是的逻辑也是脑神经一步一步猜出来的?这我就不懂了。只是从表现上,如果没有特殊约束,推理模型在一步一步猜的时候会显得生硬,比如一个简单的问题它可能也会强行拆出来好多步,一步一步猜。我倾向于还是把大模型的推理过程与人类的推理过程区分开来。
R1-Zero:纯粹的强化学习
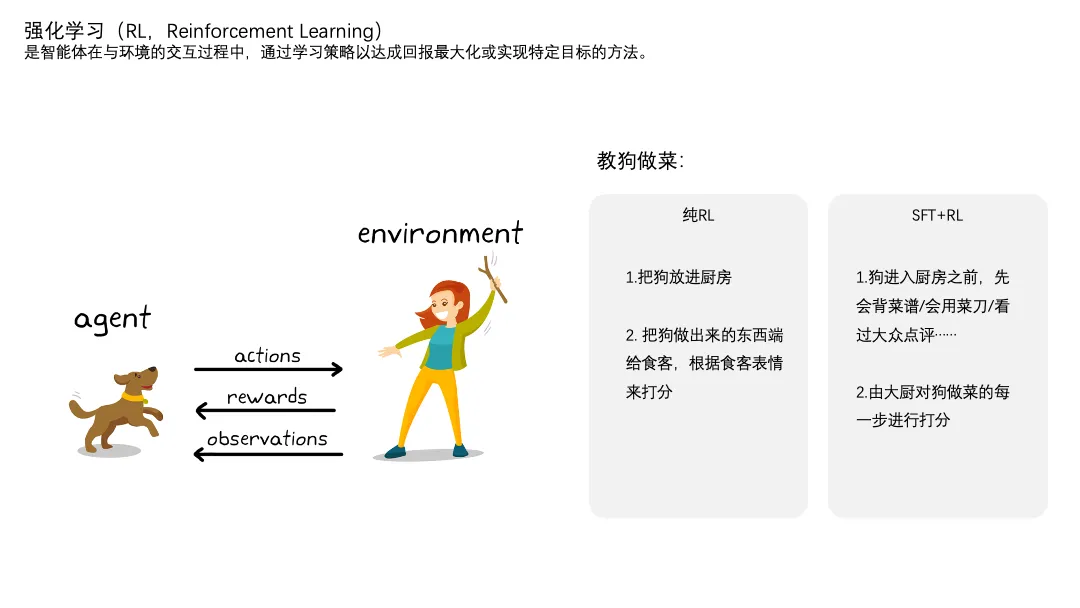
为了让DeepSeek-V3变得更好,引入了一种方法——强化学习(RL)。
强化学习是机器学习的一种,是智能体在与环境的交互中,通过学习策略已达成回报最大化或实现特定目标的方法。
说人话,就是让机器自己玩模拟游戏,然后通过某种方式给它打分,让它不断找到提升游戏分数的方法。
RL一般会跟SFT结合,SFT后面会进行介绍。我们现在只需要知道,纯RL就是把狗扔进厨房,它做出来啥我吃啥,你根据我的表情来打分;SFT+RL就好比是先教会狗看菜谱/用菜刀/看大众点评的食客评价,然后再让它去厨房做菜,然后由专业的大厨对菜品甚至是烹饪过程进行打分。
我们玩游戏时打排位冲段位,冲不上去了就去看攻略学技术,也算是一种强化学习的过程。
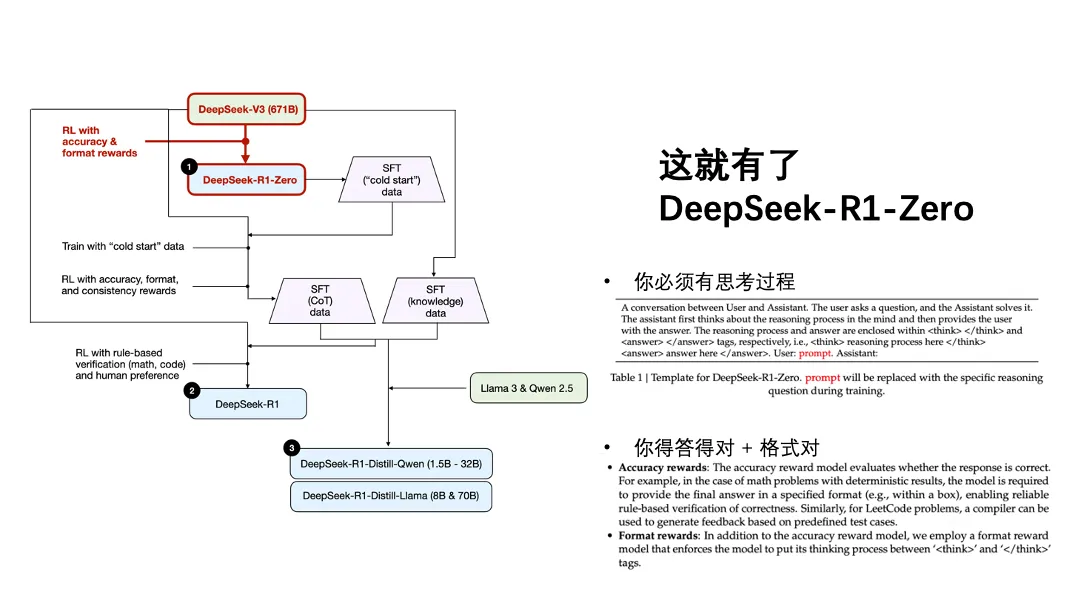
对DeepSeek-V3进行纯RL之后,就有了DeepSeek-R1-Zero。
这个过程特别纯粹、特别简洁、特别有美感。训练的过程看上去非常简单,我们只是要求了模型在思考的时候把思考过程和结果分开告诉我们,并且我们只根据回答的正确度(只看结果)和回答的格式对不对(写了“解”和“答”就给分)进行打分,不看过程对不对,没有步骤分。
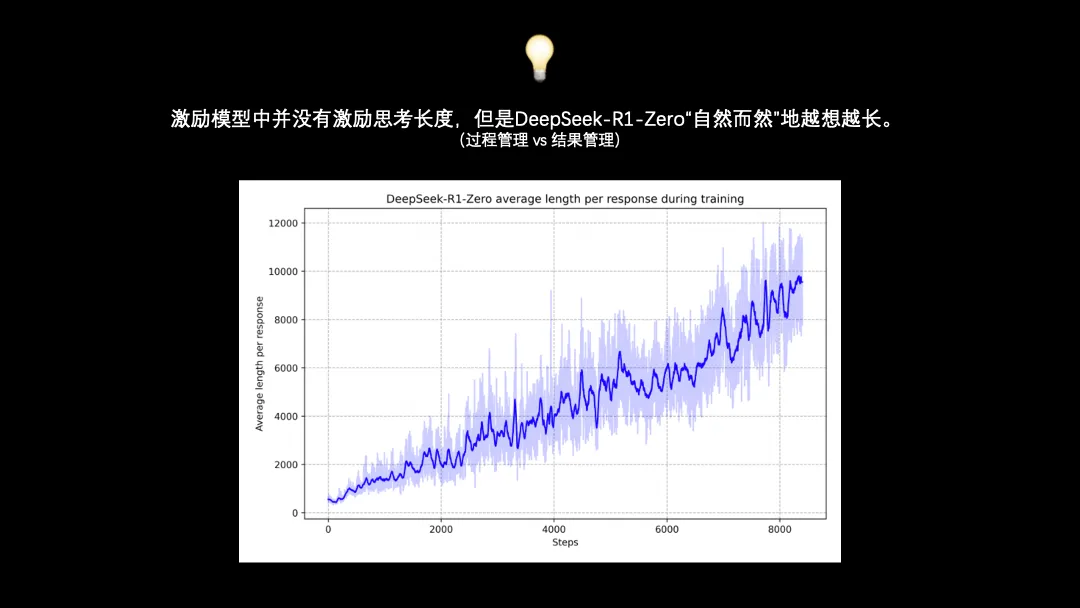
关于DeepSeek-R1-Zero,最让我起鸡皮疙瘩的一点是:虽然我们没有激励思考长度,但是大模型自己慢慢学着越思考越长了。上图可以清晰地看到,随着横轴迭代次数增加,大模型慢慢发现了,我想的越长(纵轴),更容易的高分。
这让我联想到过程管理和结果管理,如果大模型是我们的员工:
站在我们的视角向下管理,还真的是结果管理就行了,插手越多管的越乱,只要激励合适,优秀员工会自然而然找到超出我们预期的合理过程。
但是站在大模型的视角向上管理,比如别管回答正确与否,现在我总会觉得没有告诉我思考过程的豆包,表现得比告诉我思考过程的DeepSeek蠢不少。所以呢,站在员工的角度,及时向上汇报、把过程暴露给上级,好像确实是正向收益很高的举动。
有趣,实在有趣。
R1 - 微调、进一步强化学习
DeepSeek-R1-Zero像天赋很高的刺头员工,有很多小毛病,比如中英混杂、格式混乱,所以下一步要给它“立规矩”。
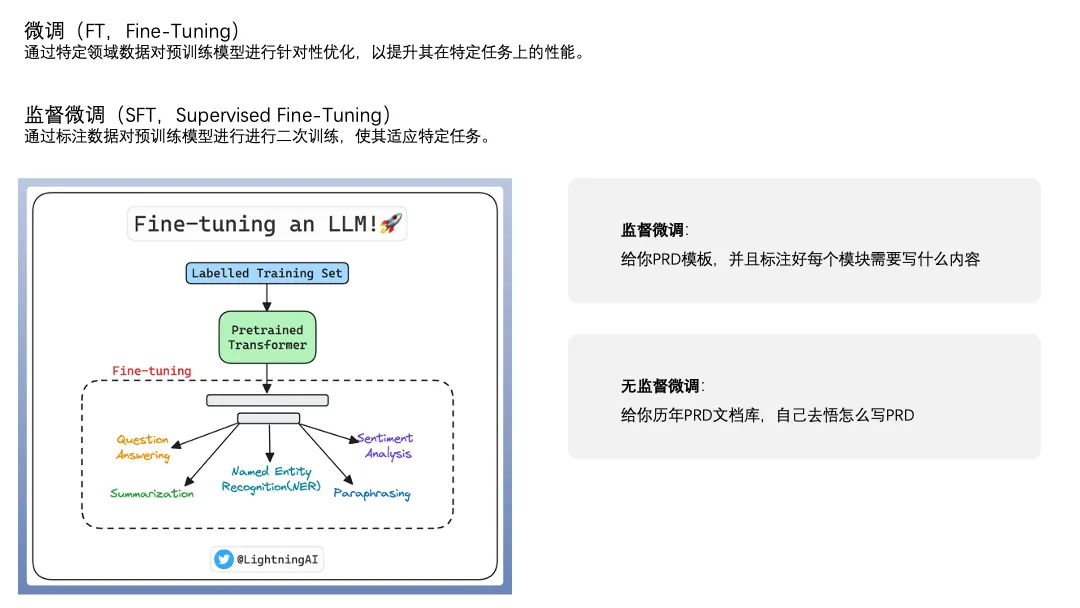
微调(FT)就是常用的给大模型立规矩的方法,能够强化大模型在某个特定任务上的能力。
微调分为监督微调(SFT)和无监督微调,以产品经理举例,监督微调就是给实习生一些优秀的PRD模板,并且模板里面标注好每个模块要写什么内容、怎么写,无监督微调就是给实习生一个历年PRD文档库,他自己去悟应该怎么写PRD。
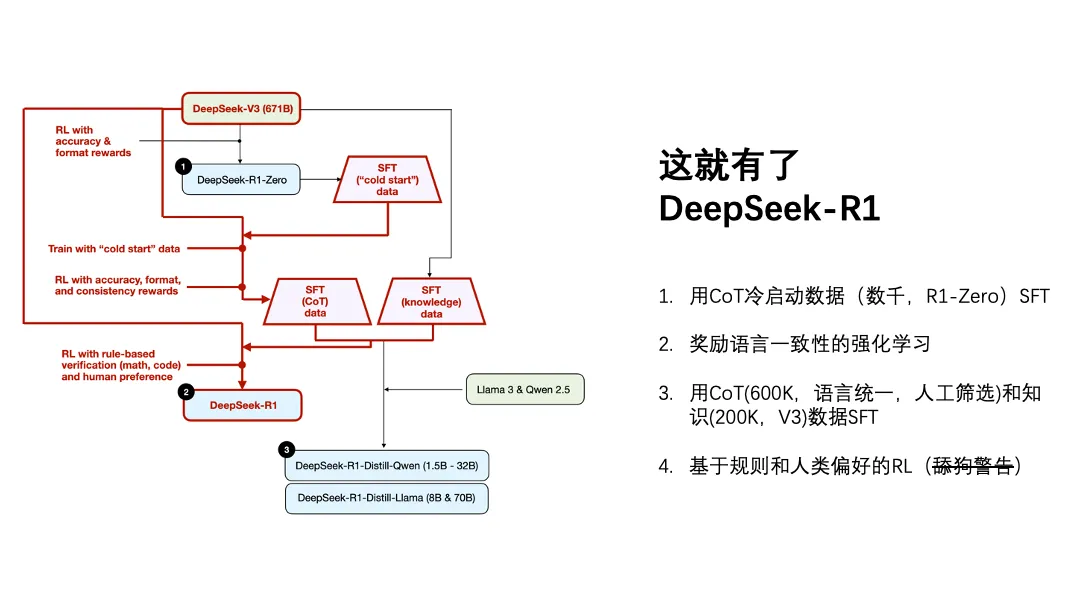
DeepSeek-R1的训练过程要更复杂一点,分成几步,但这几步在我看来也是非常有美感的,用张涛的话说“左脚踩右脚”。
第一步,用已经验证有效的DeepSeek-R1-Zero产生了数千条CoT冷启动数据。
第二步,强化学习,相比训练DeepSeek-R1-Zero那次,奖励的标准除了答得好、写「解」「答」以外,还奖励了语言一致性,就是别中英混杂。
第三步,用了60万条经过人工筛选的CoT数据,以及20万条由DeepSeek-V3产生的知识数据,再次进行强化学习。跟上次的强化学习不同,又增加了数学、代码类的规则以及人类偏好。
最终把DeepSeek-R1训练成了一个说话很好听的聪明人。

使用DeepSeek-R1时,我经常被震撼到。作为一个经常写作的人,我第一次感受到人工智能的文采远超于我。
上图的图片是有一次我找DeepSeek咨询时,它结尾说的话,我坐在卫生间马桶上,老泪纵横。
你……你真是老舔狗了……舔的真好啊……
但是,DeepSeek-R1的幻觉率超级高,在Vectara HHEM的测试中,R1的幻觉率是V3的四倍,而V3看起来也略超过行业平均水平。
所以,“创意”和“误差”是一体两面吗?
这让我想到另外一个未经验证的认知,好像很多有才华的人更容易患上精神类疾病?
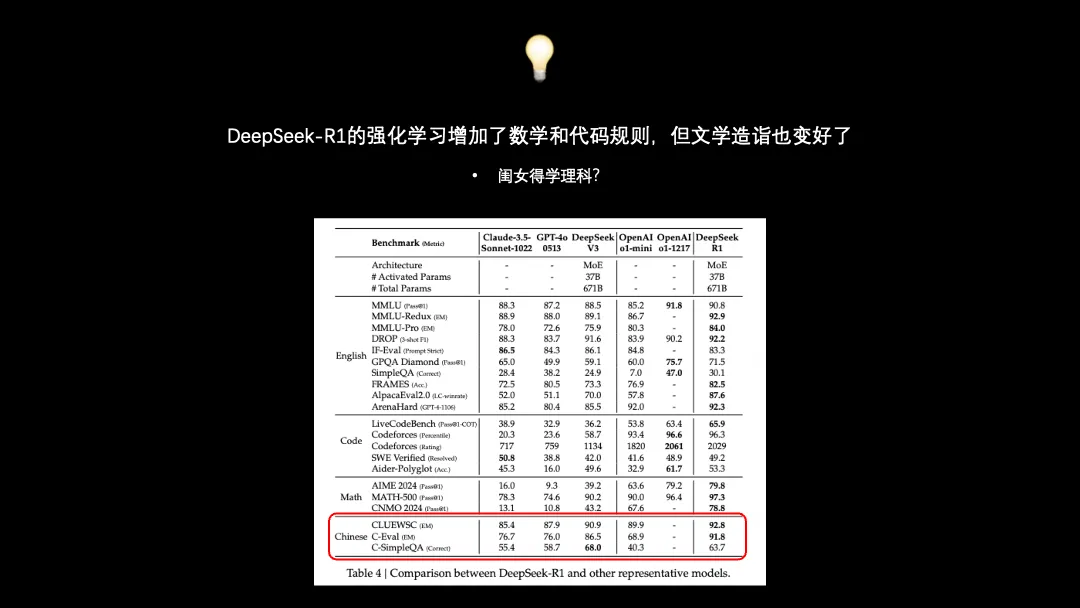
除此之外,犬校里Trendol的话让我头皮发麻:看起来DeepSeek-R1的强化训练过程主要输入了数学和代码的规则,但是它出人意料地在文史哲类问题上取得了足够出圈的成绩。相信大家都能有相关的体感,DeepSeek改写文章、帮助取名字、写脱口秀段子手到擒来。
毕达哥拉斯所言非虚,“万物皆数”?再想一步,我们的世界有没有可能是被计算出来的呢?
或者有可能是那堆精心标注的CoT数据立了大功(网传DeepSeek的CoT数据标注工作找了不少北大中文系的学生),所以理科学规律,文科练笔杆,真不愧是一帮中国学霸做出来的东西。
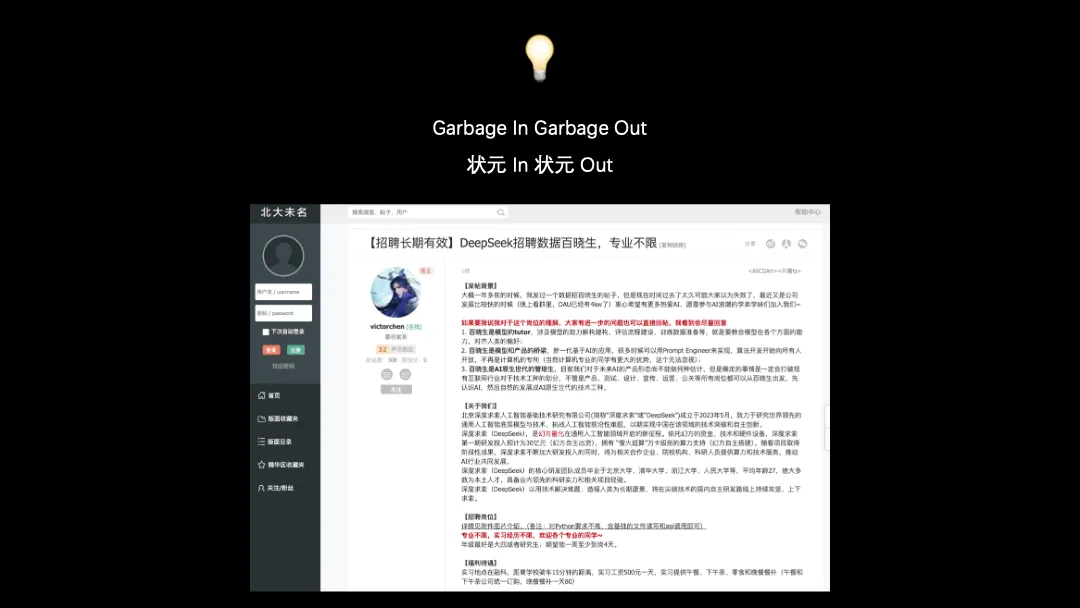
DeepSeek有一个岗位叫“百晓生”,请文科状元提问题、搞标注。有一句话叫“Garbage In Garbage Out”,是说低质量的数据(错误的、重复的……)对大模型来说是有毒的,那么“文科状元 in”,岂不就是“文科状元 out”了。
一些微小的工作:蒸馏、RAG、其他
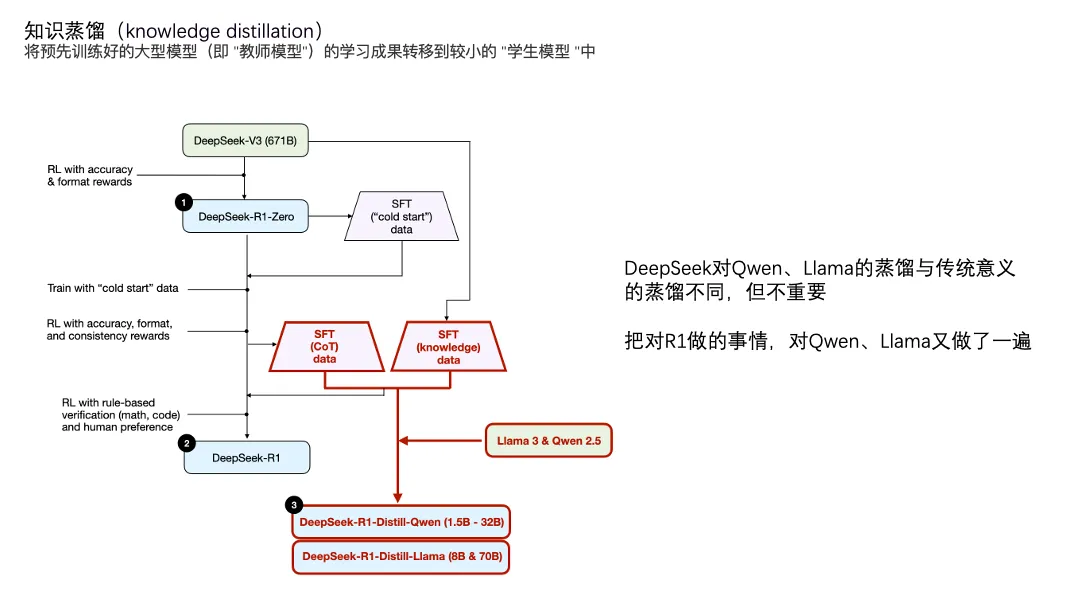
大模型领域的蒸馏是指将大模型的知识传递给小模型的过程。大模型一般性能好,计算量和存储量也会有更高要求。那么就拿大模型的训练数据、结果数据及其中间过程喂给小模型,让小模型学会跟大模型一样思考,在性能不会降低太多的前提下,显著降低计算成本。
上面的过程,我理解更像“言传”。
DeepSeek的蒸馏过程更像“身教”。某种程度上,DeepSeek-R1像是被DeepSeek-V3和DeepSeek-R1-Zero两位老师训出来的,那么两位老师不变,把学生换成阿里的Qwen和Meta的Llama来试一下。
这就有了DeepSeek-R1-Distill-Qwen和DeepSeek-R1-Distill-Llama。
有趣的来了。
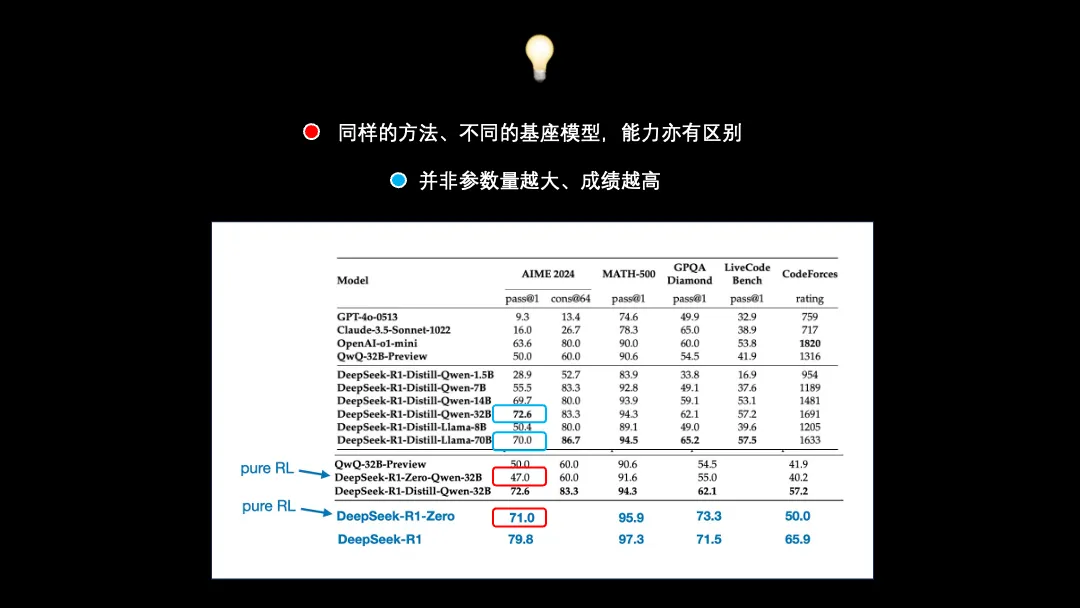
首先,老师不变,学生换了。看上图蓝框里面的数据,Qwen和Llama这两位学生在同样的老师下,得分亦有高低。甚至说,参数量更少的Qwen(32B)在某些时候的表现还要好于参数量大了一倍多的Llama(70B),属实是村里的骄傲了。(英伟达:我心疼啊。)
另外,除了蒸馏以外,DeepSeek-R1-Zero不是DeepSeek-V3用纯RL学出来的吗?那就让Qwen也用纯RL的方式自学一遍,说白了,教材没变,换个学生来念。结果训出来的成绩不忍卒读,远低于自学成才的DeepSeek-R1-Zero和名师辅导的DeepSeek-R1-Distill-Qwen(红框数据)。
只能说选用预留,选字当头了。一流的人才是培养不出来的!

无论是成绩上还是流程上,我们都能看出一个很容易骗人的概念,DeepSeek-R1-Distill-Qwen虽然名字一开头就是DeepSeek,但它本质上不是DeepSeek的模型,基座模型仍然是阿里的Qwen。很多厂商说自己继承了DeepSeek,很多车企宣称实现了DeepSeek上车,是李逵还是李鬼,有没有蒸馏过,怎么蒸馏的,这里面门道多了。
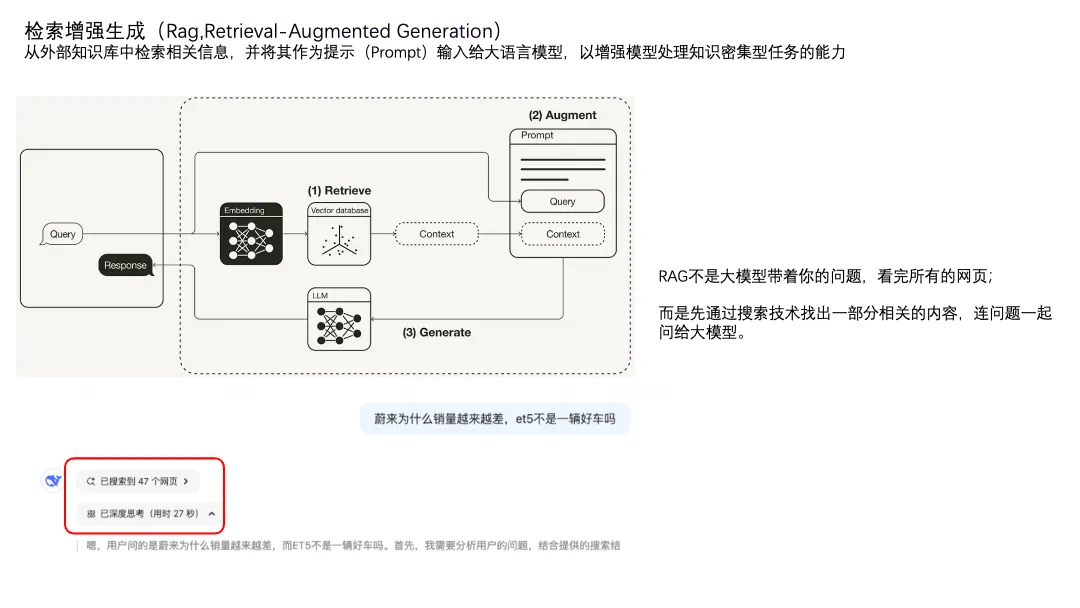
检索增强生成(RAG)是另外一个有趣的能力,就是用个外挂数据库,让大模型除了问题以外,还能结合数据库里面的信息进行回答。
“联网搜索”就用到了RAG。我之前以为的“联网搜索”是大模型带着我的问题,检索很多内容,挑出来其中价值高的整理成回答。后来发现不是这样,RAG是先用搜索技术找到一些内容,再把这些内容作为额外的上下文连同原始问题一并输入给大模型。从左下图也能看到,是先找一些参考网页,然后才基于这些网页进行的思考。
用原理来说,由于这些网页的内容跟提示词一起,组成了上下文的部分,而上下文的长度又会影响大模型计算的性能,所以让一个有智能的大模型在互联网之海中遨游,最终给出高实时性、高准确度的答案,在目前的架构上看起来性价比很低。所以是先用一些“笨笨的”方法,帮大模型找到对解题可能最有帮助的几本教辅书,然后大模型才开始读题、翻教辅书。
这里有个显著的业务问题。其实我用DeepSeek的联网搜索没那么爽,因为DeepSeek检索的内容源一般来自门户网站的新闻页面,对于一些专业类问题来说,这些网站的内容太业余了。但是秘塔集成的DeepSeek检索的内容源就经常出现一些行研、用研的报告,还能直接找到pdf原文下载。所以专业类的问题我一般都直接用秘塔了,也立刻停止了一些报告类网站的付费会员。
所以如果我们的业务需要用到大模型,自己公司的预训练能力到底强不强,在我这里可能并不是个很重要的评价项。反而是否有独特资源、是否有深刻的业务理解,我认为是更重要的因素。
RAG这里还有个注意点,就算外挂了数据库,RAG也不像人类一样是翻着字典找答案,RAG仍然是猜,只不过谜面多了一些从数据库中检索的内容。并且检索的过程也相对简单,利用余弦相似度等方法,找相似向量,向量来源于原始文本向量化,所以检索精度有限。如果没有额外的规则,我们依靠大模型从某个数据库中算数,比如根据一堆本地的excel做统计,一般不会有太好的结果。CoT会对此有帮助,但考虑到我们不知道幻觉何时发生,验算的工作量不一定比自己手算的小。
再延伸一点,豆包提供了一个很好的思路,大模型先理解数据、分析需求,然后编写Python代码并执行,最后得出结论。大模型发挥了agent的作用,调用合理的工具解决对应的问题。犬校有个讨论是“大模型会颠覆传统搜索吗?”,我的理解是大模型与搜索技术不是相互替代的关系,而是相互赋能。在大模型的加持下,无论是搜索技术还是搜索场景都会有更多可能性。这些可能性之前可能都要靠繁琐的规则或人力来完成。

除此之外,DeepSeek-V3的训练过程中还有一些非常非常有趣的概念,搞懂这些概念的过程让我感受到一群天才是怎么在层层约束下追求极致的。上面这些概念除了在张涛的公众号《潜云思绪》中有通俗的解释,Ray在DeepSeek原始论文的解读中也给出了很详细、很通俗的解释,非常非常值得一看。从DeepSeek 9篇论文的解读中学点什么(上)
作为产品经理,为什么要了解这些技术概念呢?我觉得至少有两个原因,其一,了解了解这些概念能帮助我们更好理解供给侧竞争力是如何产生的。其二,这里面很多设计都是来源于“没卡”这个问题,本质上还是个业务问题。
后记:一点诳语
去年年初有一次跟同为产品经理的朋友聊天时,他们觉得Openai已经绝了,并且ChatGPT很快会遇到瓶颈。但是呢,2024年9月,Openai就发了推理模型o1,跟之前的模型相比,性能大幅提升。结果这不到半年,DeepSeek就发了R1,还是中国的、开源的,产生了一系列连锁反应。
我对大模型整体是非常乐观的,这一定是个长期的、上限极高的事情,因为全世界这么多顶尖聪明的人和炙手可热的钱都涌入这个赛道,没有进步的话只能说是人类的悲哀。
但我并非业内人士,倾向于会保持一个身位的距离:如果我们没有押上身家孤注一掷的魄力和能力,那就保持学习、保持关注,直到大模型开始实实在在影响到我们所在的行业。到那个时候,我们可能就是自己行业里最领先的那部分人了。
推荐阅读
通识课:
张涛 - 分享文章:万字赏析 DeepSeek 创造之美:DeepSeek R1 是怎样炼成的?
张涛- 原视频:最好的致敬是学习:DeepSeek-R1 赏析
Ray - 从DeepSeek 9篇论文的解读中学点什么(上):
从DeepSeek 9篇论文的解读中学点什么(上)
本科专业课:
Andrej Karpathy - 深入探索像ChatGPT这样的大语言模型:https://www.bilibili.com/video/BV16cNEeXEer/
3Blue1Brown - 直观解释注意力机制,Transformer的核心:https://www.bilibili.com/video/BV1TZ421j7Ke/
研究生专业课:
Sebastian Raschka - 理解推理模型:https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
DeepSeek官方论文 - DeepSeek-R1通过强化学习激励 LLM 中的推理能力:https://arxiv.org/pdf/2501.12948