为什么 DeepSeek 出来可以轰动全世界,而差不多功能的字节跳动的豆包却没什么人关注?
二者不一样哈,差远了,不是同一类大模型
字节的豆包是普通大模型
deepseek R1 是推理大模型
这意味着
核心目标不一样
豆包:文本生成、基础问答、信息检索
DS:多步骤逻辑推理、复杂问题解决、因果分析
训练数据不一样
豆包:通用语料(网页、书籍、对话等)
DS:增加逻辑题、数学题、科学推理等结构化数据
训练方法不一样
豆包:自回归语言建模
DS:结合思维链(CoT)、程序辅助、符号逻辑增强
输出特点不一样
豆包:流畅但可能缺乏深度逻辑
DS:结构化、分步骤、注重因果链推导
所以,豆包和deepseekR1压根儿没有可比性
举个例子你可能就明白了
鸡兔同笼问题


从鸡兔同笼问题的回答我们可以看出,虽然结果一样,但,deepseek的思维链展示更加清晰完整。
如果你还不能理解deepseek的伟大,那我再给你举一个语料库被污染的典型例子
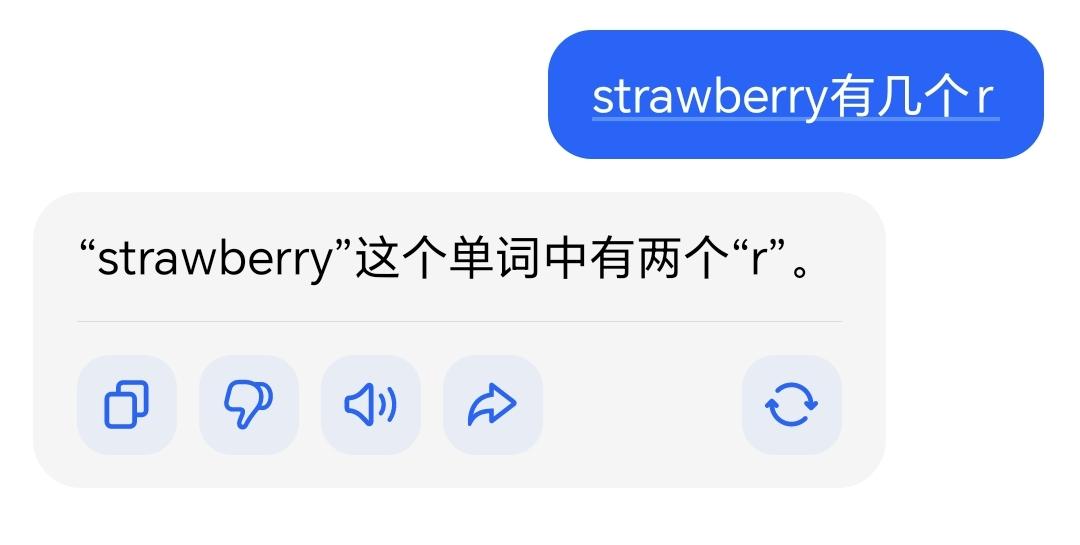
看,你们吹嘘好用的豆包,成傻子了吧!

看,这就是deepseek的牛逼之处,就算语料库被污染了,她也能通过自己的思考得出正确的答案。
来和高手学习一下

感谢 @野火吃腰果 提供的调试思路
再看一个比大小的问题R1表现如下

关于字母统计的问题,我们看看豆包怎么说
第一步,让豆包承认传统生成式大模型存在缺陷

好,豆包投降了,我们趁热打铁,问问豆包,传统生成式大模型还有哪些缺陷,应如何克服

好,这是豆包告诉我们的真相,我们不能只相信一面之词,还要问问deepseek,看看这个火出圈的家伙怎么说
关于英文字母统计的问题

ds很开明,不仅把原因公布了出来,还把如何解决公布了出来,就这一点ds就可以吊打世上大多数生成式ai了!
作为普通人,我们只能通过提高自己的提示词编写技术,来让ai输出更加精准的答案,比如ds给出的改进建议:清逐个字母统计分析
关于生成式大模型的缺陷问题

以豆包为首的普通生成式大模型,你们好好学学吧,自己有问题不敢直接面对,怎么进步,还得让竞争对手拿鞭子抽?AI工程师们,加油努力吧,方法都有了,就看你们怎么改进了
别光说别人不好,我们看看DS在这些缺陷上的进展现状

这还不够,你敢承认自己不行吗?

厉害了,不仅承认了自己的不足,还给出了,例子,原因,和用户应对建议!我就喜欢这样的AI,开诚布公的让我知道AI得不足,我就可以有的放矢的提升自己的专项技能,让AI变得更好,但,豆包这类传统生成式大模型总是藏着,掖着,生怕用户知道它的不足,你连自己的弱点都不敢面对,你咋进步呀!
通过这一系列得沟通,我学到了很多新知识,有一些还没有完全学通透,还需要与ds进行更加深入的沟通,探讨,验证…