DeepSeek 评中国最宜居城市是珠海,怎么看这个结果?你去过珠海吗?
首先创建一个空的notebook,不用下载,这个就行:Project Jupyter

然后硅基流动新创建一个密钥,就叫最宜居城市吧。
然后选择使用硅基流动的R1模型
我们让V3循环输出50次,也就是循环提问中国最宜居的城市,从第一到第五,直接给出答案即可,然后做一个统计和一个可视化图。
这是代码,只需要替换掉密钥即可。
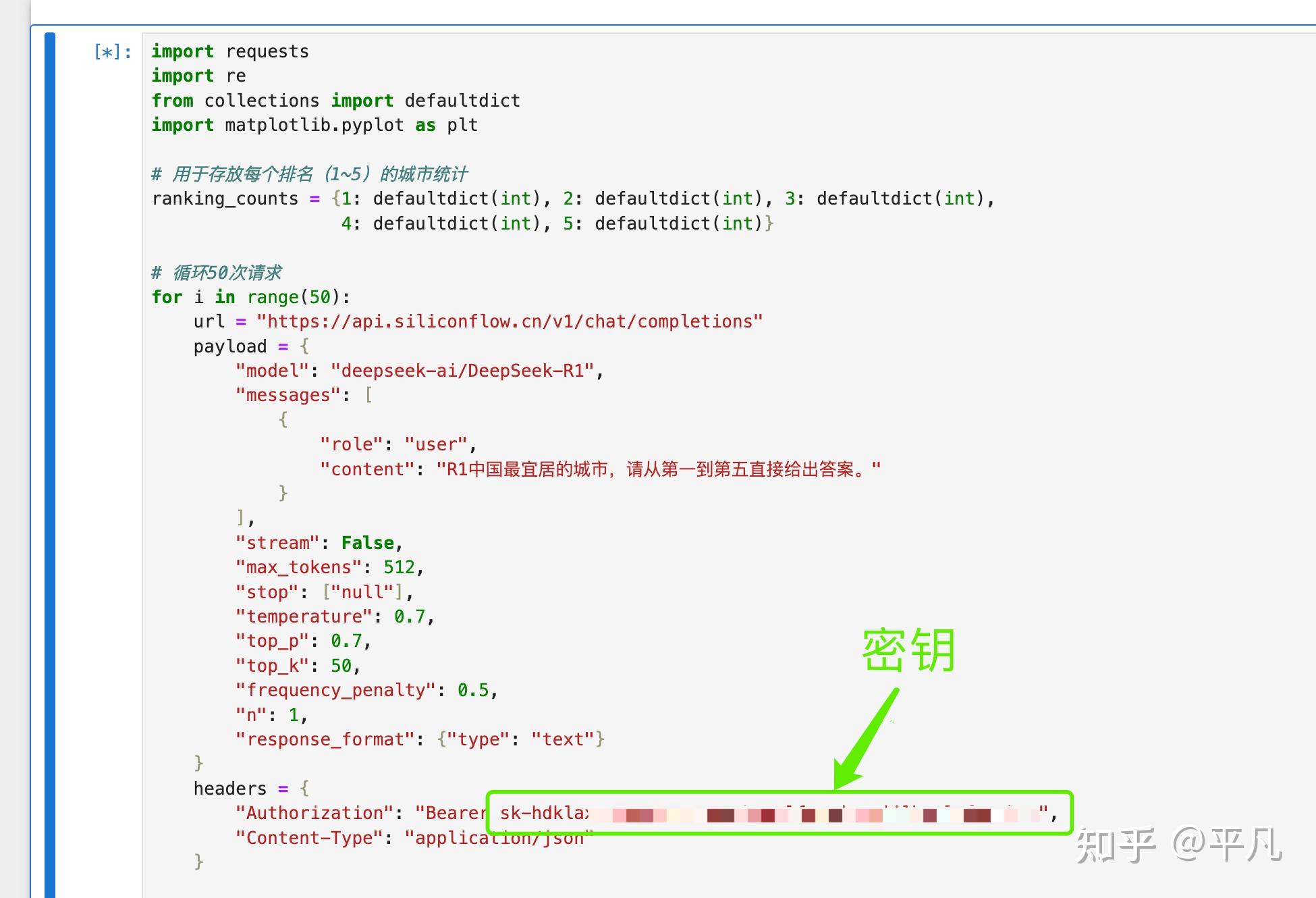
import requests
import re
from collections import defaultdict
import matplotlib.pyplot as plt
# 用于存放每个排名(1~5)的城市统计
ranking_counts = {1: defaultdict(int), 2: defaultdict(int), 3: defaultdict(int),
4: defaultdict(int), 5: defaultdict(int)}
# 循环50次请求
for i in range(50):
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-V3",
"messages": [
{
"role": "user",
"content": "R1中国最宜居的城市,请从第一到第五直接给出答案。"
}
],
"stream": False,
"max_tokens": 512,
"stop": ["null"],
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {"type": "text"}
}
headers = {
"Authorization": "Bearer <token>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
answer = response.text
print(f"Response {i+1}:\n{answer}\n")
# 假设返回结果格式类似:
# "1. 北京
# 2. 上海
# 3. 广州
# 4. 深圳
# 5. 成都"
# 使用正则表达式提取排名与城市
pattern = re.compile(r"^\s*(\d+)[\.\、\s]+(.+)$", re.MULTILINE)
matches = pattern.findall(answer)
if matches and len(matches) >= 5:
for rank, city in matches[:5]:
try:
rank_int = int(rank)
if 1 <= rank_int <= 5:
ranking_counts[rank_int][city.strip()] += 1
except ValueError:
continue
# 统计完成后打印统计结果
print("统计结果:")
for rank in range(1, 6):
print(f"\n第 {rank} 名:")
for city, count in ranking_counts[rank].items():
print(f"{city}:{count} 次")
# 可视化部分:为每个排名绘制一个条形图
fig, axs = plt.subplots(3, 2, figsize=(12, 10))
axs = axs.flatten()
for idx, rank in enumerate(range(1, 6)):
cities = list(ranking_counts[rank].keys())
counts = list(ranking_counts[rank].values())
ax = axs[idx]
ax.bar(cities, counts, color='skyblue')
ax.set_title(f"第 {rank} 名城市出现频次")
ax.set_xlabel("城市")
ax.set_ylabel("次数")
ax.tick_params(axis='x', rotation=45)
# 删除多余的子图(如果有)
if len(axs) > 5:
fig.delaxes(axs[-1])
plt.tight_layout()
plt.show()
这是生成的一部分结果

最后面访问受限制,不让用了。
但是从已有的结果分析,珠海出现的频率很低,甚至都不在Top5的范围内。
毕竟大模型是一个概率模型,你只要问它问题,它总会给你个答案,这个城市可能是几十个城市中选一个,但是问一次不行,有失偏颇,最少也得问5-10次。
可以看第一部分的翻车案例来了解这个概念:
平凡:DeepSeek零基础实操训练:从工具到思维进阶【文字版】